Hello all,
I am using a combination of fmriprep, tedana, xcp_d, and fsl_feat to generate a preprocessed BOLD image from multi-echo fMRI images for TMS targeting.
I am using a pipeline that has successfully run for four sets of subject data up to this point, but for some reason, it is not going so smoothly for this dataset.
Everything is running as expected up to xcp_d, but the denoised output from xcp_d is missing practically all relevant signal. I am passing the ica_mixing_file generated by Tedana to xcp_d as a custom regressor that contains only the components that we would like to remove, typically around 500 columns (components) by 800 rows (volumes) (all but 50 or so BOLD-identified components). We are also passing fmriprep output as the input to xcp_d.
After xcp_d finishes running, the voxel values in the output image are around 10-12 orders of magnitude smaller than expected - we’re getting +/- 0.000000000001 as the range of voxel values, when we’re expecting (and have previously achieved with this same pipeline and call) a range of +/- 1000.
I’ve been in contact with @tsalo and his thought was that xcp_d is regressing ALL signal rather than just the non-BOLD components, but we have rerun Tedana and xcp_d multiple times for this dataset with some adjustments to the inputs and mixing files and continued to get the same result. I tried rerunning Tedana and xcp_d for other subjects whose data was already successfully used for targeting and was able to achieve the expected output.
I’m wondering if anyone has experienced this before, or if there are any ideas as to where this issue may be occurring, or if anyone has any more suggestions for troubleshooting.
Command used (and if a helper script was used, a link to the helper script or the command generated):
#Tedana plus ica_reclassify, happy to provide the rest as an attachment if needed, as it is rather long
tedana -d "$Subdir"/func/rest/"$DataDirs"/Rest_E*_acpc.nii.gz -e $(cat "$Subdir"/func/rest/"$DataDirs"/TE.txt) --out-dir "$Subdir"/func/rest/"$DataDirs"/Tedana/ \
--tedpca "$MEPCA" --fittype curvefit --mask "$Subdir"/func/rest/"$DataDirs"/brain_mask.nii.gz --maxit "$MaxIterations" --maxrestart "$MaxRestarts" --seed 42 --verbose # specify more iterations / restarts to increase likelihood of ICA convergence (also increases possible runtime).
ica_reclassify "$Subdir"/func/rest/"$DataDirs"/Tedana/desc-tedana_registry.json --manacc "$Subdir"/func/rest/"$DataDirs"/Tedana+ManualComponentClassification/AcceptedComponents.txt --manrej "$Subdir"/func/rest/"$DataDirs"/Tedana+ManualComponentClassification/RejectedComponents.txt --tedort --out-dir "$Subdir"/func/rest/"$DataDirs"/Tedana+ManualComponentClassification/
#XCP_D singularity call
singularity run --cleanenv \
--no-home \
-B ${jobTmpDir}:/tmp \
-B "/appl/freesurfer-7.1.1:/freesurfer" \
-B "/project/oathes_analysis2/R61/Liston-Laboratory-MultiEchofMRI-Pipeline-master/MultiEchofMRI-Pipeline:/bidsfilt" \
-B "/project/oathes_analysis2/templateflow:/templateflow" \
-B ${input_dir}:/data/input \
-B "/project/oathes_analysis2/R61/working_dir:/data/working_dir" \
-B "/project/oathes_analysis2/R61/ica_mixing_files:/customconfounds" \
-B ${output_dir}:/data/output \
/appl/containers/xcp_d-0.6.3.simg \
/data/input /data/output participant --participant_label $1 \
--work_dir /data/working_dir \
--bids-filter-file /bidsfilt/bids_filter_file.json \
--fs-license-file /freesurfer/license.txt \
--nthreads $2 \
--omp_nthreads $3 \
-vvv \
--input-type fmriprep \
--smoothing 6 \
-c /customconfounds \
-p custom \
--despike
Version:
Tedana - v23.0.2
xcp_d - v0.6.3
I know the xcp_d version is fairly outdated. I am planning to look into updating it after our current batch of participants is finished since it is working reliably for every other dataset.
@jdickson14 firstly, super sorry about failing to respond via email. I got distracted and forgot.
The ICA mixing file from tedana includes both noise and signal components. You need to select components from that mixing file based on the classifications in the component table (desc-tedana_metrics.tsv). From your description it sounds like you passed the file along without modification.
Also, 500 components seems really high. What PCA option did you use in your tedana calls?
No worries! I didn’t follow up because I thought I found another reason for the errors and ran with that, but still no dice.
As for the confound file, there is another step that I omitted from the description. We are generating the mixing file using a Python script - I’m not sure if our old data analyst put it together or if we got it from somewhere but this is the body of it:
import pandas as pd
import numpy as np
import sys
sub = sys.argv[1:][0]
class_file = '/project/oathes_analysis2/R61/' + str(sub) + '/func/rest/session_1/run_1/Tedana+ManualComponentClassification/desc-tedana_metrics.tsv'
classification_metrics = pd.read_csv(class_file, sep='\t')
accepted_components = []
for index,row in classification_metrics.iterrows():
if row['classification'] == 'accepted':
accepted_components.append((row['Component']))
ica_file = '/project/oathes_analysis2/R61/' + str(sub) + '/func/rest/session_1/run_1/Tedana+ManualComponentClassification/desc-ICAOrth_mixing.tsv'
ica_components_mixing = pd.read_csv(ica_file, sep='\t')
renamed_columns = {}
for col in ica_components_mixing:
col_name = ica_components_mixing[col].name
num = col_name.replace('ica_', '')
col_name = "ICA_" + str(num)
if col_name in accepted_components:
#print(col_name)
ica_components_mixing = ica_components_mixing.drop(columns = col)
else:
renamed_columns[col] = col_name
ica_components_mixing = ica_components_mixing.rename(columns=renamed_columns)
print(ica_components_mixing)
file_string = "sub-" + str(sub) + '_ses-baseline_task-rest_dir-AP_desc-confounds_timeseries.tsv'
ica_components_mixing.to_csv(file_string, sep='\t')
We use it to generate the xcp_d input that only includes the components we want to regress.
As for the PCA selection, we’re using the kundu decision tree.
We’ve had around 450-500 total identified for each subject up to this one, but this one there were actually 680 ID’d. Which yes… does seem like an awful lot…
An earlier version of our pipeline used AIC for the PCA option, and generated 68 components. I’m not sure why we moved away from that but I can follow up with our PI or former data analyst to see why.
I don’t think your code is reducing the mixing matrix. I just tried it out on some tedana derivatives I had locally and, while the mixing matrix’s columns were renamed, the number of columns didn’t change.
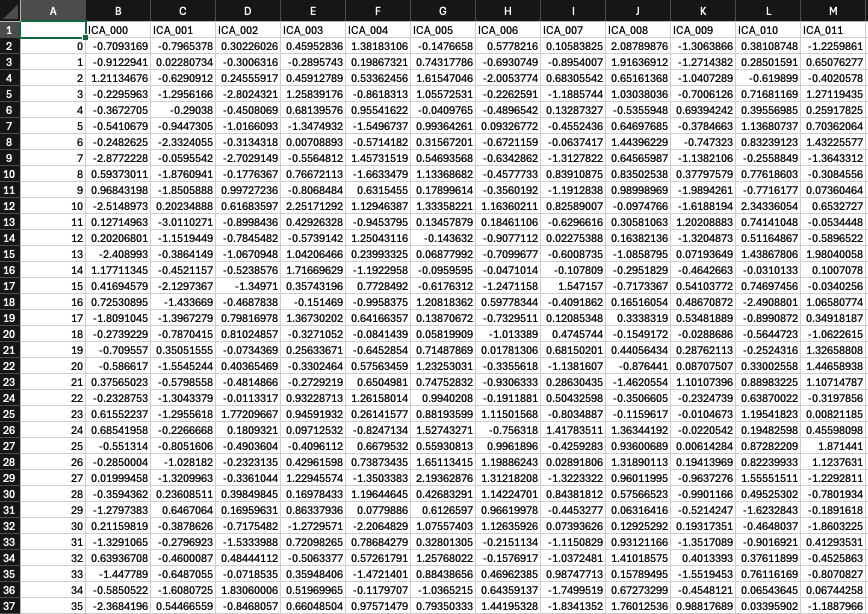
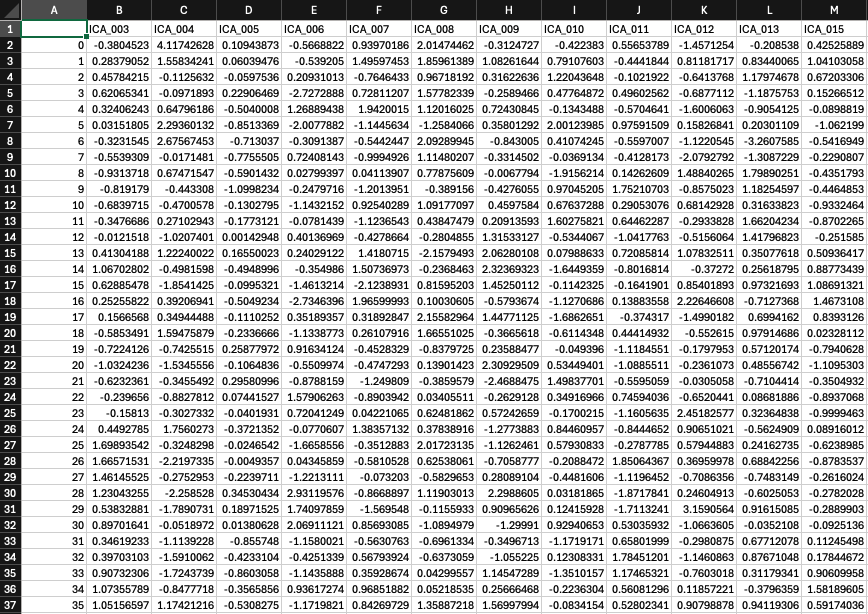
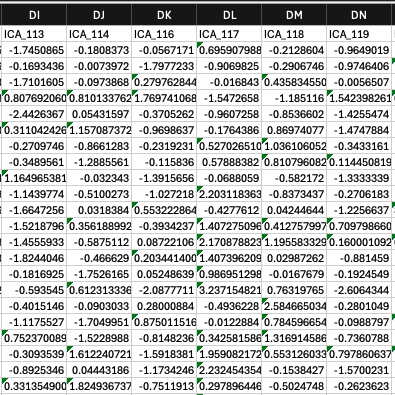
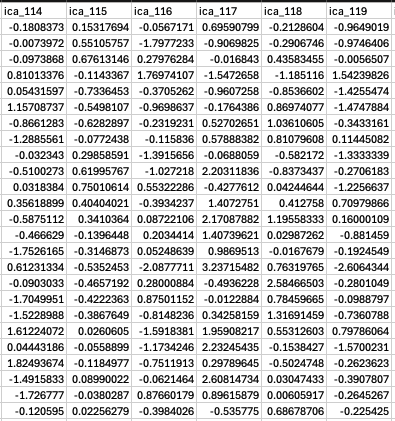
Hmm, okay. When I inspect the tsv’s visually, the columns are aligned with the accepted components removed. Tedana usually gives us 25-50 true bold components, depending on the participant - for this one it was 19. For example, in this case ICA_115 was accepted as bold. This is the mixing file generated by our script (661 columns):
Okay actually I just finished another rerun of xcp_d where I set the framewise displacement threshold to 0 just to see if that was a sticking point and I JUST got normal values in the output… it was originally cutting 265 volumes due to motion (retaining 621/886). A previous subject had some motion and xcp_d cut 204 volumes, so I’m wondering what the cutoff point is, or if it’s patient-dependent. It is possible that this is too few volumes to be viable, but I will have to check with my PI. Any thoughts on that? We are planning to rescan the participant next week, so either way I will likely have another chance but I’m open to expert opinion!
Maybe you’re using an older version of tedana where the column names were different. I’m glad that the confounds file looks good though.
You’re probably running out of degrees of freedom. 886 volumes - (50 nuisance regressors + 265 censored volumes + the bandpass filter, which does have a dramatic effect on DOF). @handwerkerd WDYT?
afni_proc.py keeps track of lost degrees of freedom, which is a feature that XCP-D should probably adopt.
Thanks Taylor, I’ll look into the afni_proc.py to see if we can integrate that.
Would it be worth trying to pass the framewise displacement confound generated by fmriprep to xcp_d? Their threshold is 0.5, and we’re using “auto” for xcp_d (which I believe is 0.3?). Or would it make more sense to change from “auto” to 0.5 and just let xcp_d do its thing.
Or anything else that would modify/increase available degrees of freedom. I am open to any and all suggestions!
afni_proc.py would be an alternative to fMRIPrep, rather than an extra step to incorporate. I was more referencing it as a cool feature that I should add to XCP-D at some point.
XCP-D recalculates FD, so there’s no real value in using fMRIPrep’s flagged volumes.
The key is that you just have too many noise components from tedana. I’d recommend changing your PCA setting to ensure there are fewer components in the ICA step.