Thank you again for these insights, @dowdlelt!
As for the sampling, we do need a TR or around 1s for the purpose of our experiment.
I wasn’t aware of this 2 x T2* rule-of-thumb. Thanks for bringing it to my attention.
I downloaded some online ME datasets to get a better feeling of what I might expect in our own data. This included the Multi-Echo Cambridge dataset with
TE: 12, 28, 44, 60 ms
TR = 2.47
GRAPPA 3 (I think not MB at all)
I ran fmriprep (this time with slice-timing correction due to the slow TR) and ran tedana with either all 4 echos or only the first 3 (which is more similar to our own data). I found the results quite perplexing. For example, for one subject (04570):
Tedana, curvefit, AIC, no GSR, 3 echos

with the first excluded component being (53% variance explained):
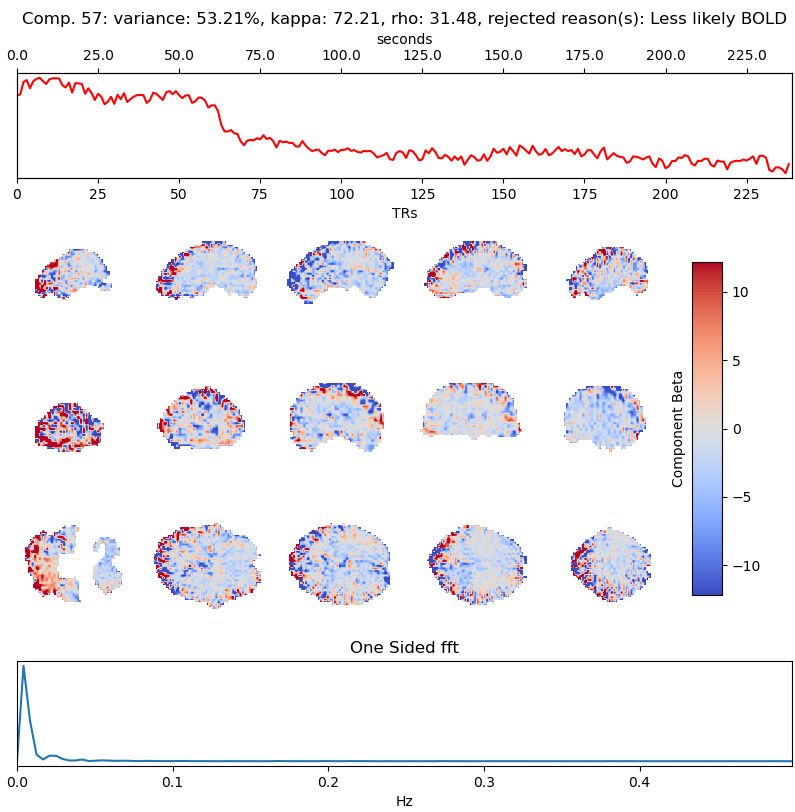
Tedana, curvefit, AIC, no GSR, 4 echos
with the 2nd accepted component (27% variance explained) being quite similar to the excluded one when we use only 3 echos:

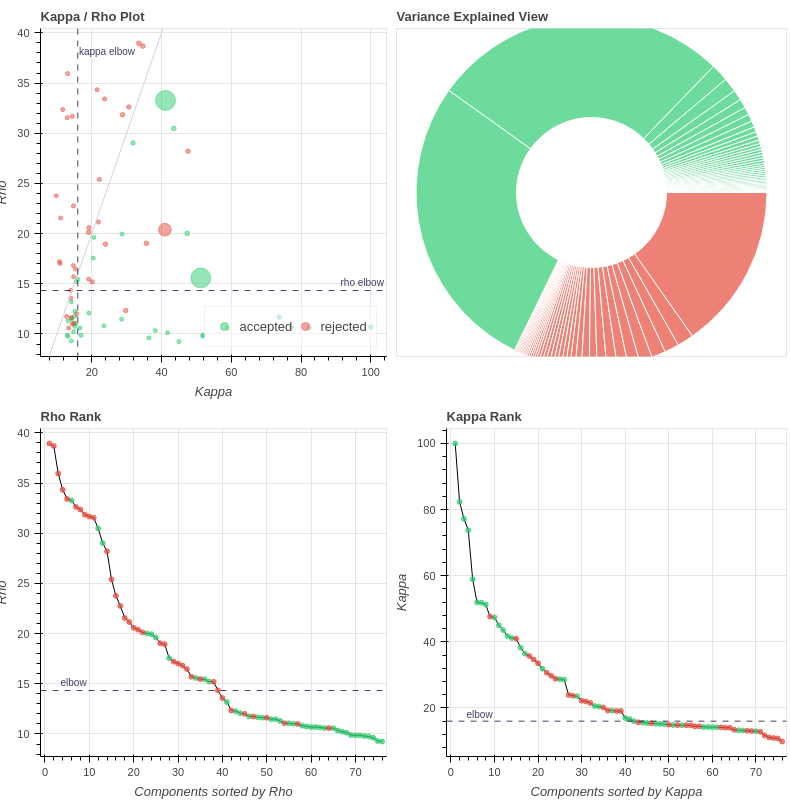
Indeed, there are many more ICs compared with our data (~75) with only 139 volumes per scan.
I’m confused by this extreme difference in tedana’s behavior when taking 3 or 4 echos.
I will also add that for some subjects (like 11310), the carpet plot for the rejected components does have a similar repetitive texture to it, like we see in our data:
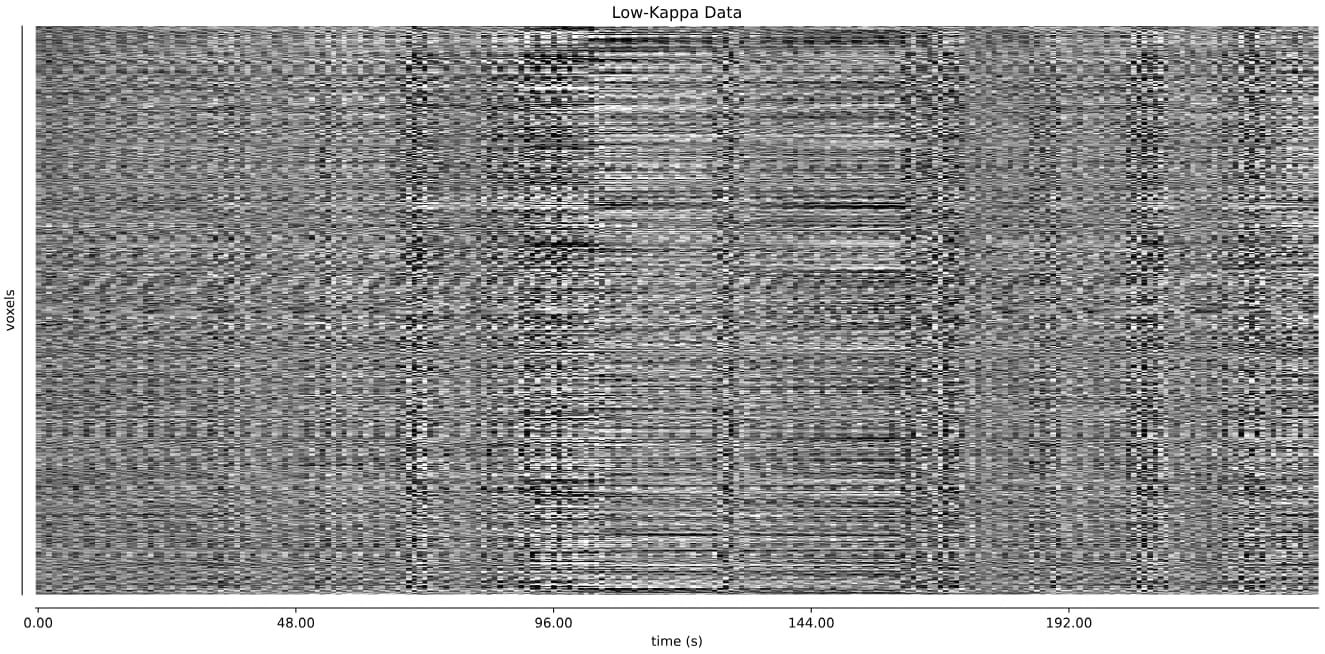
Thanks for staying with me here ![]()