I am analyzing some resting-state MB-ME data (MB factor 4, iPAT (GRAPPA) factor 2, TE= 12.2, 26.8, 41.4ms) using fMRIprep, tedana and XCP-D following this example. Specifically, I used a modified confound regressor file based on tedana’s ICA components with aCompCor.
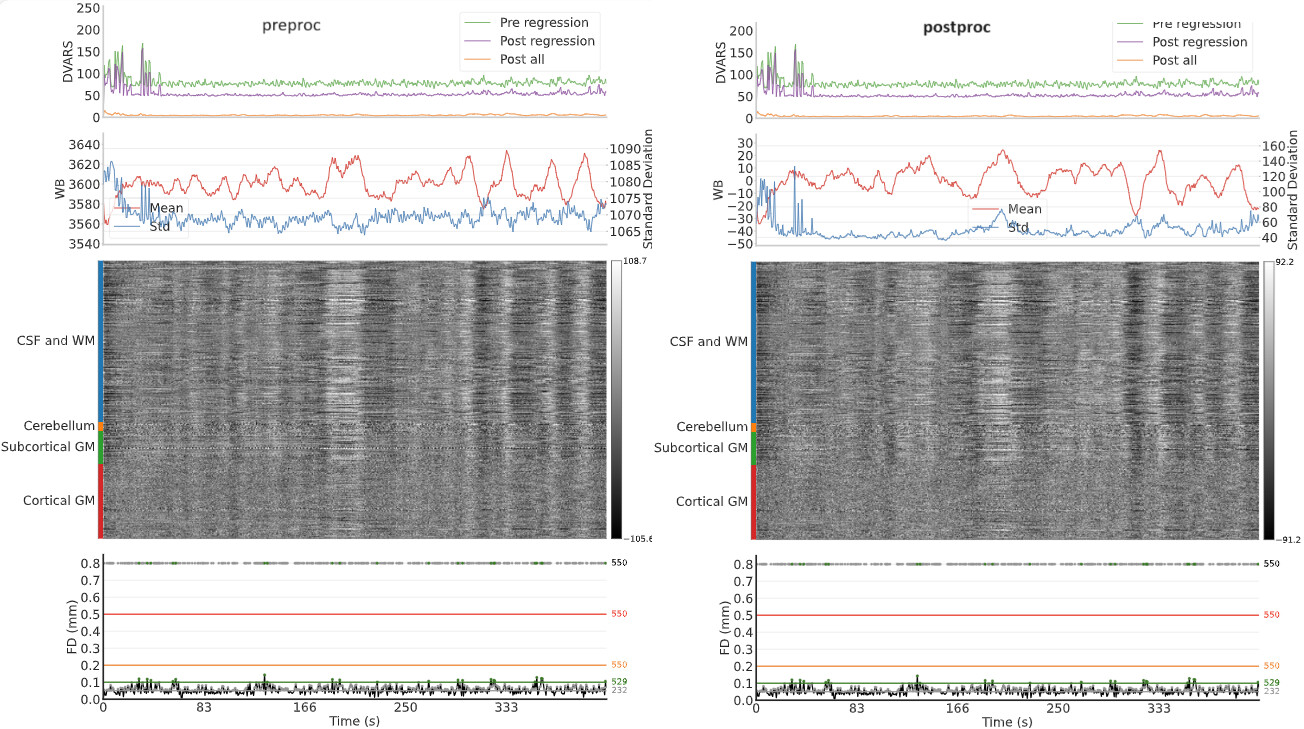
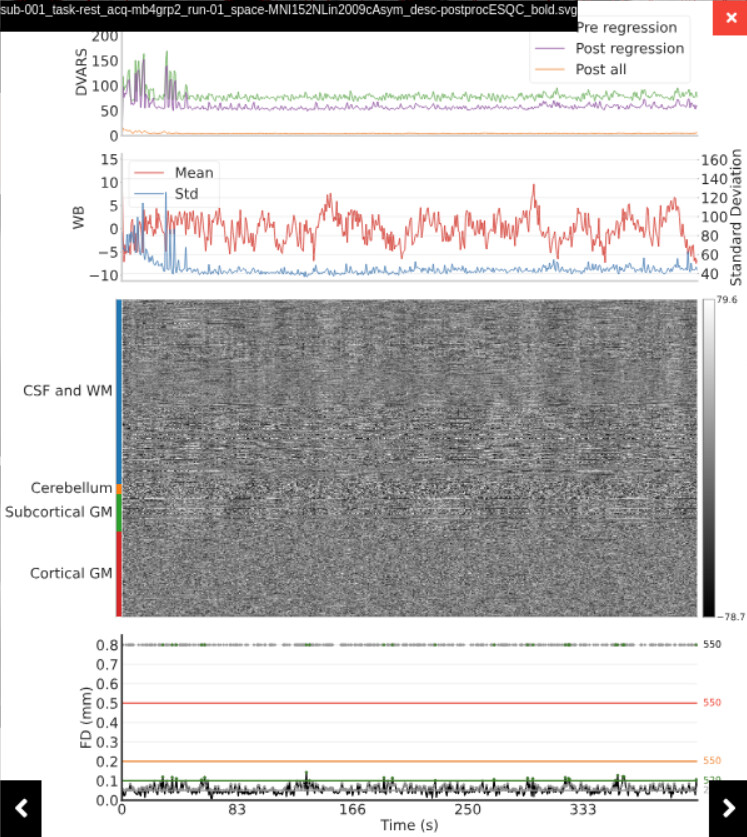
However, looking at the summary report I was surprised to see a lot of residual global signal remaining, possibly related to deep breaths or to eye closing. I was hoping that aCompCor would be enough to remove these artifacts.
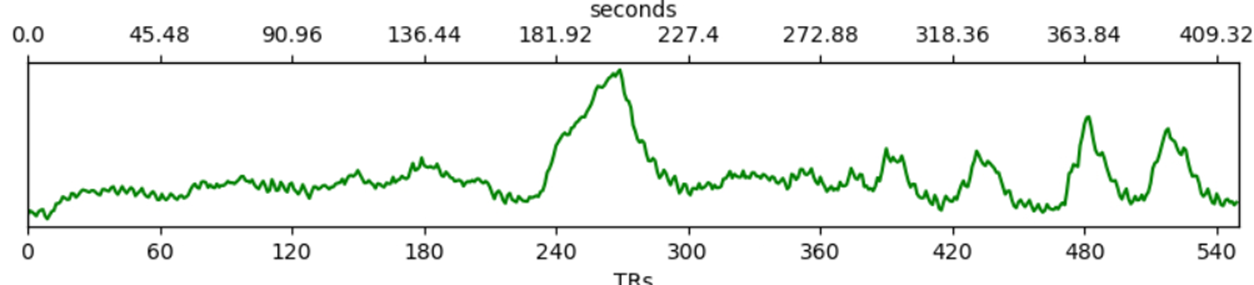
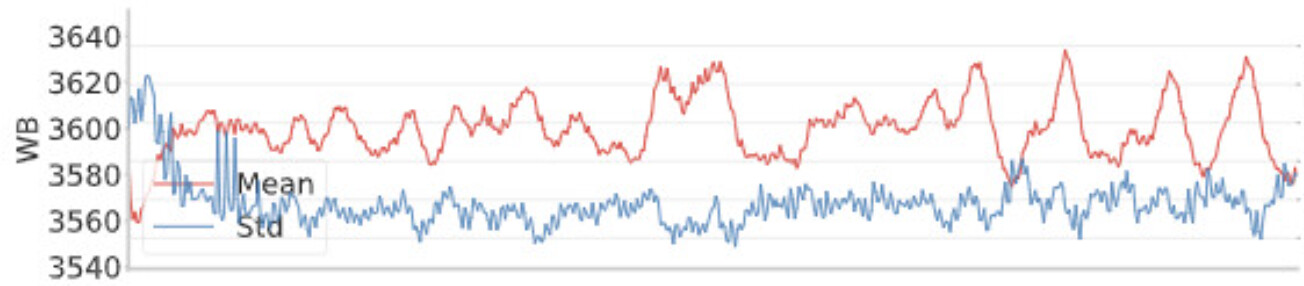
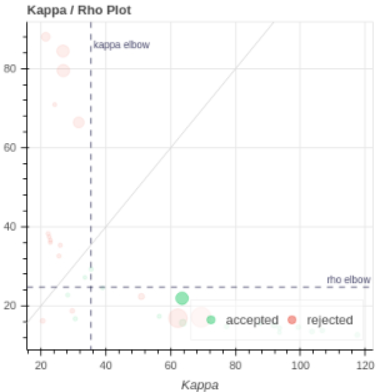
Going back to tedana’s report, I noticed that the mean time series of the first accepted component actually includes the very large whole-brain variations we see in the preprocessed data:
The position of this component on the rho/kappa space also makes it clear why this component was accepted:
However, I’m still puzzled: Since the effect of this component is evident throughout the brain, including in white-matter, I expected aCompCor to take care of this. Am I missing something fundamental here?
That definitely explains things. The components you flag as “signal” in the custom confounds file will be used to orthogonalize each of the “nuisance” regressors- not just from the custom confounds file, but also from your nuisance regression strategy. That means that the general pattern from your high-variance accepted component there will be removed from the aCompCor regressors. Would you be willing to try the following?
Perform the orthogonalization just using the tedana components. Namely, orthogonalize the rejected components w.r.t. the accepted components. You can do this with numpy, or you can re-run tedana with the --tedort flag enabled.
Next, create a custom confounds file just including the orthogonalized, rejected components. No need to include the accepted components with the signal__ prefix.
Finally, feed in your new custom confounds file to XCP-D, as you ran it before.
Would you say this is the recommended way to go in general, since tedana seems to sometimes err on the side of false positive components (see another example from a different dataset here)?
At least, as long as we believe that aCompCor components are noise and that motion related regressors do not represent BOLD signal, this sounds fine to me, but I would love to hear your opinion on this.
Many thanks!
P.S.
For future reference, to complete step 2 in your explanation, I replaced the following lines in the xcpd-tedana example code:
# Prepend "signal__" to all accepted components' column names
accepted_columns = metrics_df.loc[metrics_df["classification"] != "rejected", "Component"]
mixing_matrix = mixing_matrix.rename(columns={c: f"signal__{c}" for c in accepted_columns})
with:
# Instead of prepending "Signal__" to the accepted components, we omit them altogether, following the advice here: https://neurostars.org/t/summary-report-of-xcp-d-using-multi-echo-bold-and-tedana/28304/5
accepted_columns = metrics_df.loc[metrics_df["classification"] != "rejected", "Component"]
mixing_matrix = mixing_matrix.drop(columns=accepted_columns, errors='ignore')
I hadn’t considered it before this thread, but yes it does seem like orthogonalizing before calling XCP-D is the way to go. The only alternative would be for tedana users to manually review and correct the component classifications, as tedana cannot flag BOLD-based noise signals (like global signal).
There are a few options in tedana for global signal control (--gscontrol gsr and --gscontrol mir), but I haven’t played with them much, so I don’t know what impact they would have on the final set of components.
Thanks @tsalo, Your advice was very helpful!
Just to make sure I’ve got this right:
This current pipeline only uses the ME-ICA outputs of tedana (to regress out the noise components). It does not incoporate the optimal combination of the different echos. To achieve this, I could either:
Transform the optimally combined data to MNI152NLin2009cAsym space, and then run XCP-D, which will now also analyze this newly created file. or…
Tranform each echo separately to MNI152NLin2009cAsym space, then run XCP-D, and finally optimally-combine the transformed+regressed echo files.
Since all steps are linear, I lean towards the simpler option 1.
I’d greatly appreciate it if you could point any flaws in this pipeline.
(the reason I’m asking is that I don’t see a great difference between single-echo acqusition with XCP-D and multi-echo acqusition with tedana+XCP-D in terms of within-network coherence (which I assumed should now be higher) and between-network connectivity (which I assumed should now be lower).
I believe the recommended pipeline would be to use the optimally-combined output from fMRIPrep, which, if you requested standard-space outputs, should be in a standard space.
That way, you don’t have to transform anything.
I can’t speak to the within-network and between-network connectivity measures, sorry. I might maintain a resting-state functional connectivity workflow, but I typically use task data to validate denoising methods. Maybe @dowdlelt could weigh in on your findings? Assuming you’re not covering the same topic in Compare two protocols for TEDANA.