I have run fmriprep (Docker-based) on a Resting State fMRI dataset (ie. participant level, re-using existing FreeSurfer results, SDC) with version 21.0.2 and later on version 21.0.4.
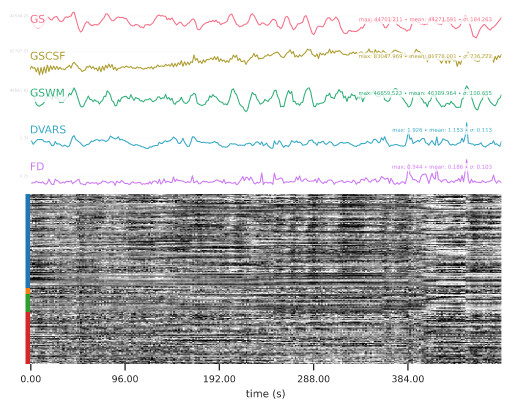
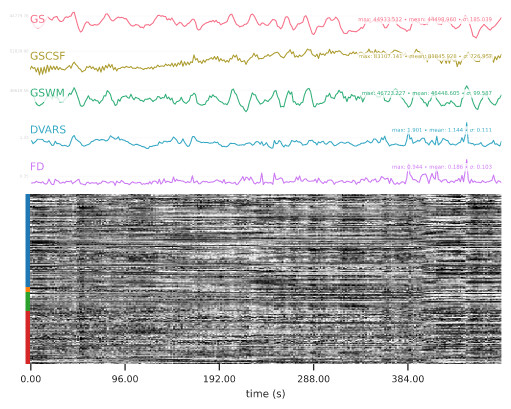
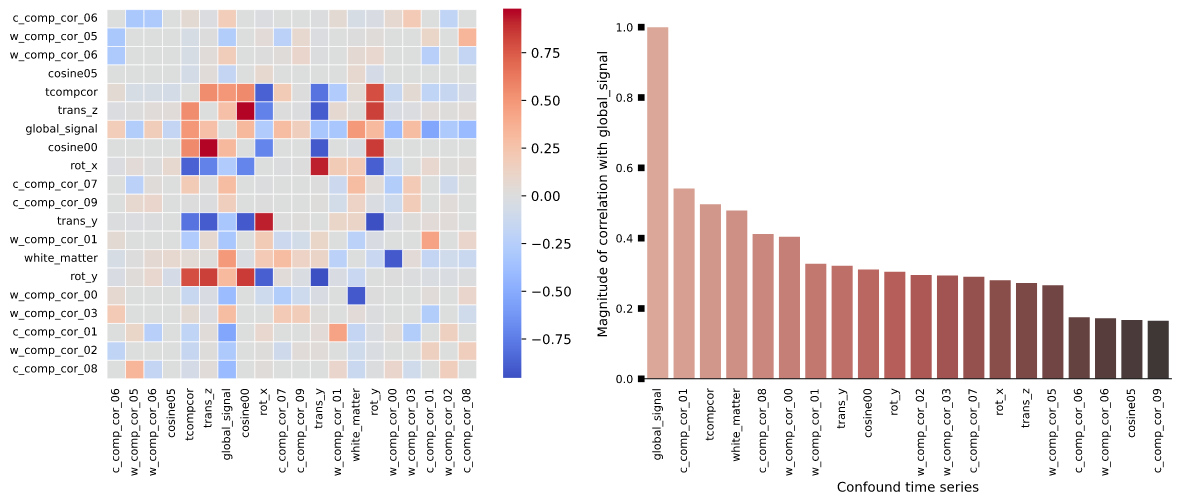
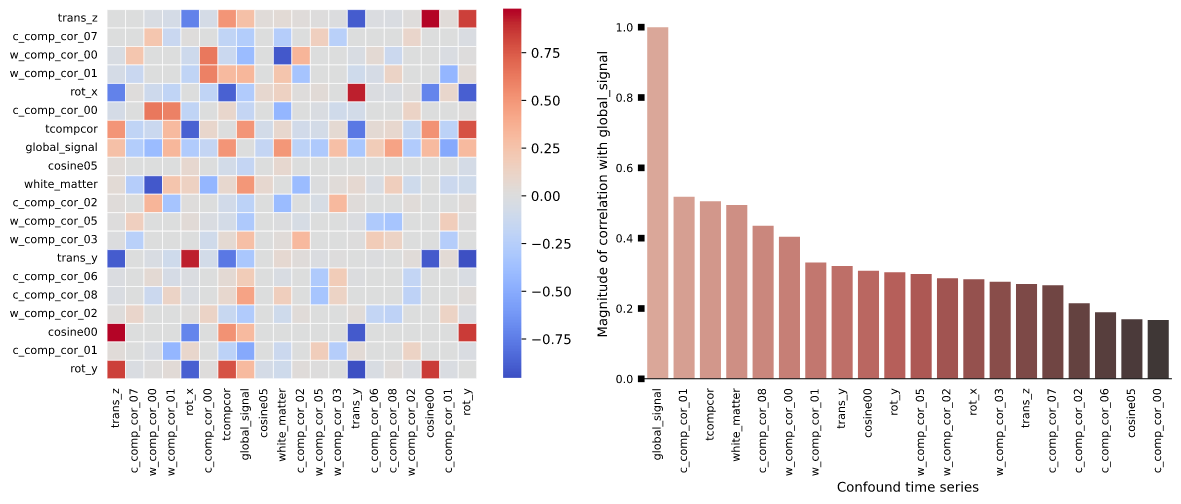
The output results were sensibly different, principally -based on the QC reports- for the BOLD carpet plot showing the time-series and the heatmap plot depicting correlations between confound variables. See below.
Btw, ICA components (obtained via --use-aroma) were also classified distinctly.
At first sight, what looks different is the display of the carpet plot and the correlation matrix between matrices, mostly due to different ordering of their elements (order of voxels or order of confounds).
This discussion has some elements than are interesting about this topic:
On the whole, I’d say these don’t look dramatically different, and agree with @jsein that it’s likely mostly a plotting issue combined with expected levels of non-determinism. We have recently fixed the random ordering of the correlation matrix, which I believe was in the 22.1.0 release.
As to the carpet plot, are you able to do an actual voxel-by-voxel correlation (you might want to do 1 - corr to get a distance measure so 0 = same, 1 = uncorrelated, 2 = anti-correlated) between your BOLD time series? I suspect that you’ll probably see high correlations (low correlation distance) everywhere except right along the boundary of the brain mask, where some voxels switch to in/out of mask. It is plausible that even a few voxels flipping between in and out-of-brain will be enough to significantly change which voxels are selected for plotting in the carpetplot, as it’s based on a decimation algorithm and will be sensitive to ordering.
Will carefully check those interesting links you shared, @jsein.
I suspect that you’ll probably see high correlations (low correlation distance) everywhere except right along the boundary of the brain mask, where some voxels switch to in/out of mask.
Yes, that’s precisely something I’ve noticed (ie. masks do not fully match across versions, see below), particularly for voxels in the cortical areas.
It depends on your situation. If 21.0.2 has been working for most of your dataset and 21.0.4 fixes issues with the rest of your dataset, then it makes sense to upgrade to 21.0.4.
If you haven’t run most/all of your data, then yes, I would upgrade to the latest version. We will also be releasing 23.0.0 in the very near future. You can try out 23.0.0rc0 right now.
I wonder how much change on those masks you would get if you were running the same version of fmriprep twice on the same subject. Could you try that?
I did it and there are indeed result changes across re-runs of the same version (eg. brain masks, confounds plots and even the intensity values of the final preprocessed bold image). Differences are very subtle but still looks like there’s some sort of stochastic process that affects having a perfectly reproducible output.
The fmriprep.toml config. file which registers the seeds used by the pipeline show different values (probably randomly generated). So I assume that setting those to a fixed value would bring me closer to fully reproducible results. Can seeds be fixed via the --random-seed argument?
If you haven’t run most/all of your data, then yes, I would upgrade to the latest version.
Good. I would prefer a stable/tested release, plus seems like series 22.1 include several SDC-related fixes and uses FreeSurfer 7.2 internally –which is the same version we used for generating FS results being fed to fmriprep. So I think we’ll go for 22.1.
Yes. There are two sources of run-to-run nondeterminism: random seeds and within-process threading. If you want identical results, you need to run with a consistent --random-seed argument and --omp-nthreads 1. (Note that --nthreads is a cap on among-processes threading. This is safe to have at a higher number or leave as default, as each process is isolated.)