These are the outputs (surface reconstruction) of FMRIPREP run twice on the same data (sub-001 and sub-150).
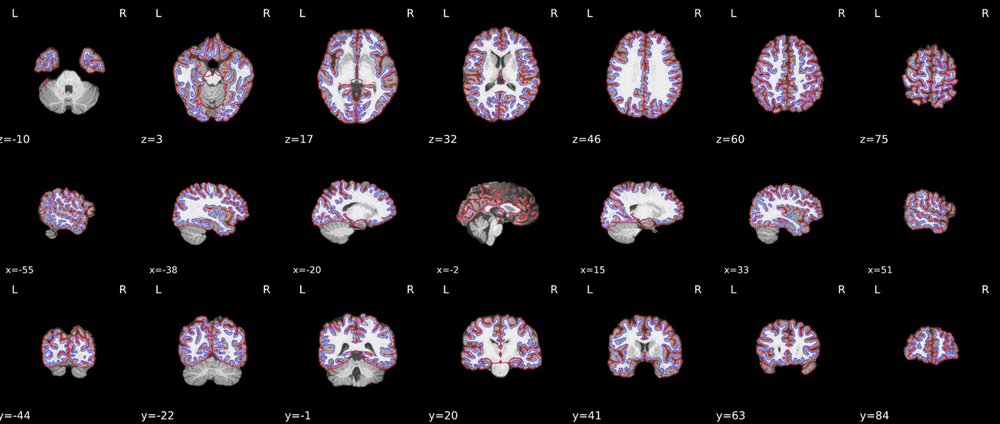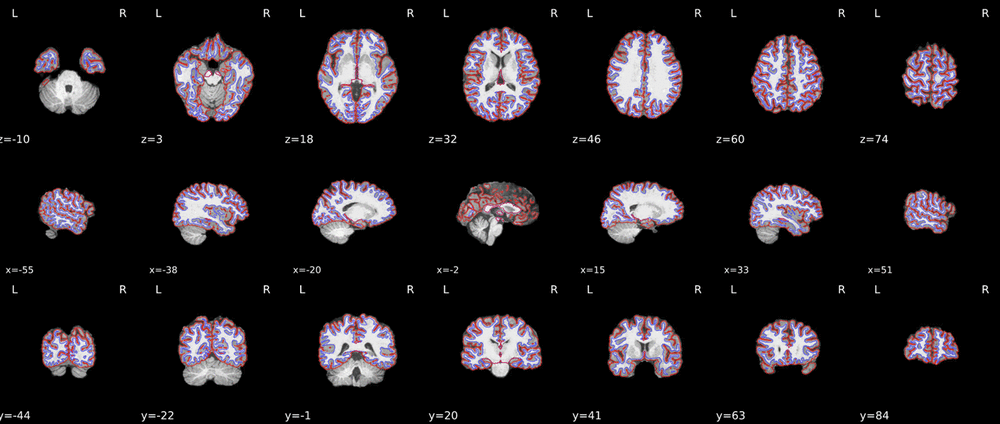
The results are almost same but little bit different for each other.
These are the outputs (MNI_LM) of ciftify-toolbox run twice on the same two data separately (sub-001 twice and sub-150 twice).
Result of sub-001

Results of sub-150

The results are also little bit different but almost same for each other.
In summary, big difference of results (difference between sub-001 and sub-150 after ciftify-toolbox; position of red and blue brain region) may be caused by fmriprep (maybe recon-all step?).