Hi,
I did fmriprep + ciftify-toolbox on same data sometimes to check reproducibility on same computer.
I checked the results by using ciftify_recon_all in ciftify-toolbox.
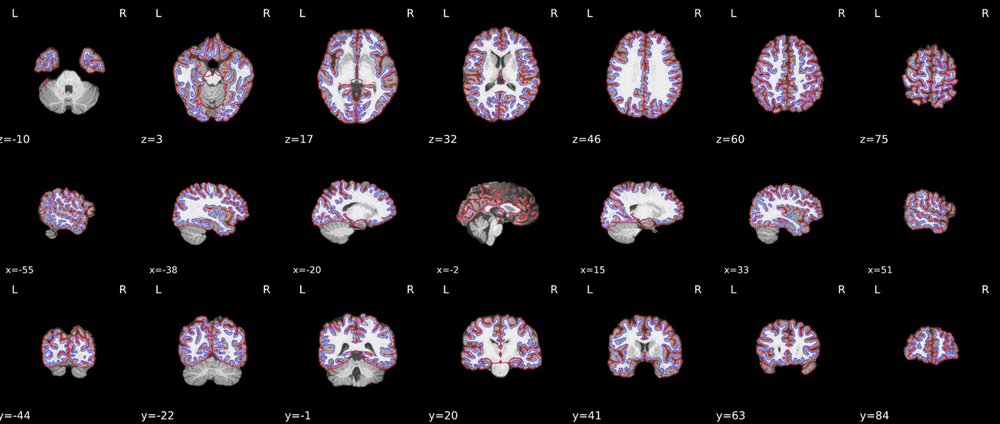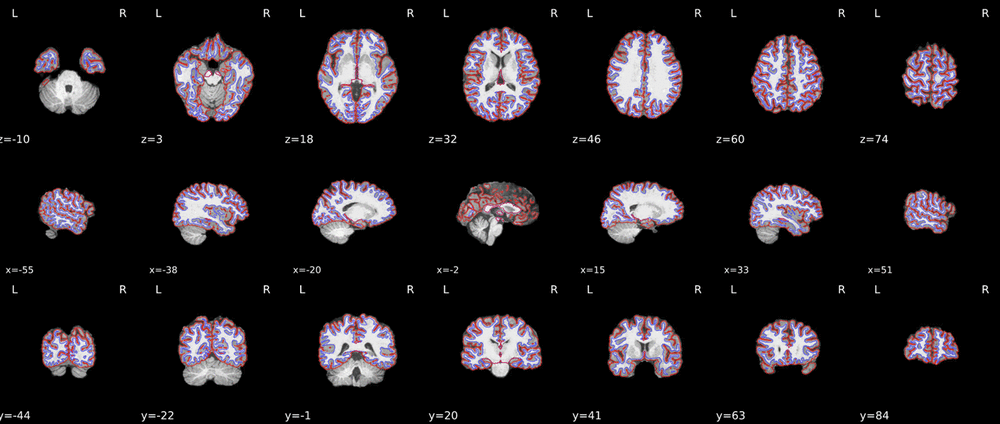
I noticed that the results were visibly different in “Midthickness Surfaces in MNI Space - with Automatic Parcellation”.
I used docker for fmriprep like below,
docker run -ti --rm -v datafolder:/data:ro -v outfolder:/out poldracklab/fmriprep:latest /data /out participant --participant-label 150 --use-aroma
What could be the reason for this failure at reproducibility?
Thank you so much,
I’m not really good in spotting differences in the images, but I noticed that the top panel is described as “sub-001” and the lower as “sub-150”. Is it possible that you choose a different subject label before?
The second column is different indeed. I’m not really an fmriprep user, so will let others to help you. The only other issue I can think about right now is the image. You’re using poldracklab/fmriprep with the latest tag that changes. Are you sure you had the same image on your laptop when you run both analyses?
Thank you for your advise!
It’s very helpful for me!
You’re using poldracklab/fmriprep with the latest tag that changes.
Are you sure you had the same image on your laptop when you run both analyses?
Sorry, I don’t understand your comment.
You mean, did I run both analyses with the latest tag ? or did I run analysis with the latest tag for one data and without the latest tag for the other data?
So the tag latest, as the name suggests, is often used for the latest version of the software. So when the fmiprep team updates software it updates the poldracklab/fmriprep:latest image. That means that if you pulled the image a month ago and again you pull it today you can have a different image with a different version of software. If you want to be sure that you’re using the same version of software, you should use images with more precise tag, e.g, 1.0.8. (see the list of tags from docker hub).
But I do not know if the difference you see could be explained by different version of the fmriprep image. This is just a general comment.
Might be worth dissociating FMRIPREP and ciftify effects. Compare outputs of FMRIPREP run twice on the same data. Pick one output of FMRIPREP and run ciftify on it twice and compare results.
The results are also little bit different but almost same for each other.
In summary, big difference of results (difference between sub-001 and sub-150 after ciftify-toolbox; position of red and blue brain region) may be caused by fmriprep (maybe recon-all step?).
Are the ciftify version and software envs the same for both runs? Do the first bit of the ciftify_recon_all.log files list the same packages and versions?
So, I want to use combination of BIDS-app recon-all and fmriprep for analysis!
Is it possible??
Yes. If there is already a freesurfer/ directory in the output directory given to fmriprep, then fmriprep will use that. (If recon-all was not fully run on a given subject, fmriprep will run unfinished steps, but a fully run FreeSurfer will just be checked for completeness and used as-is. This is both for the sake of efficiency and for accommodating situations in which custom FreeSurfer runs are required.)
Thank you for your comment!
I have to apologize to you. Actually, what I said (below) was wrong.
“the outputs (MNI_LM) of ciftify-toolbox run twice on the same two data separately (sub-001 twice and sub-150 twice). The results are also little bit different but almost same for each other.”
Because I ran the commands on different OS for the same two data.
Actually, the outputs (MNI_LM) of ciftify-toolbox run twice on the same two data on same OS were perfectly same, but the outputs of ciftify-toolbox run twice on the same data on same OS were little bit different.
The ciftify versions which I was used were Version: 1.0.1 and the exact environment settings are below.
When you run FreeSurfer on two “subject” with exactly same raw data you get the same results.
When you run FMRIPREP (with or without --omp-threads 1) on two “subject” with exactly same raw data you get different results.
Correct?
It seems that one of the FMRIPREP results is more similar to the stable pure FreeSurfer result. Could you share this data (the two “subjects”) so we could try to replicate this?