We are preprocessing our dataset of multi-echo scans using fMRIPrep and tedana kundu.
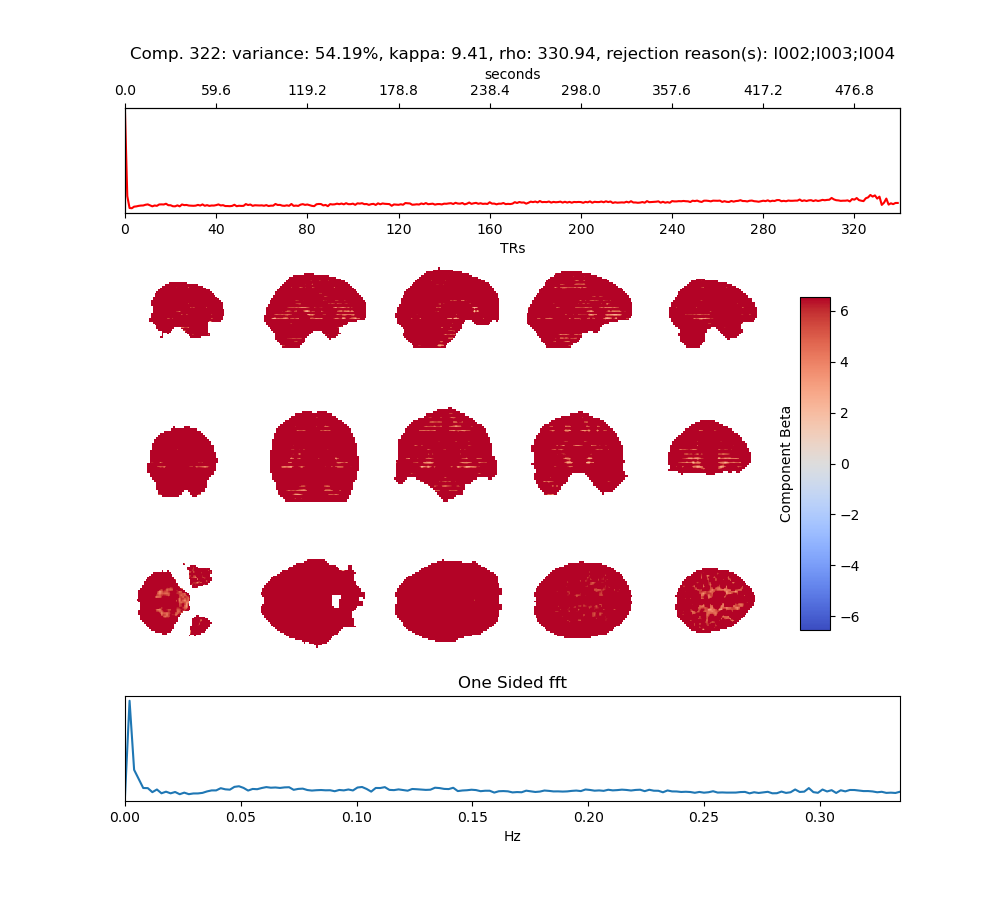
We’ve noticed that if we keep our raw images without cutting off the first couple of TRs before running denoising and combining with tedana, the dummy scans affect the components (see attached example)
We’ve had success in manually removing the first TRs from the images before running tedana, but I was hesitant to proceed this way since it would involve changing either the raw images, or the fMRIPrep output images as well as the event onsets.
Is there a way to incorporate, for example, the non_steady_state regressors that fMRIPrep provides in the tedana workflow? Would love any suggestions in how to create a reproducible pipeline while also being able to retain and share the raw data as much as possible!
You’re right, tedana does not account for the dummy scans in any way. Manually removing those TRs from the time series before calling tedana is probably the way to go for now. You’re also right that you would have to adjust the event onsets. From a BIDS perspective, you can add (or update) the NumberOfVolumesDiscardedByUser field to your sidecar JSON files to make it clear that those volumes were dropped in your tedana derivatives.
We could add a --skiptrs/--skipvols parameter to the workflow fairly easily, as long as that makes sense from a technical perspective. @handwerkerd WDYT?
My first thought for a new parameter is that it would operate thusly:
Remove the specified volumes from the data that are used for (1) adaptive masking, (2) T2*/S0 estimation, (3) PCA, (4) ICA, and (5) component selection.
Use the full data for optimal combination and denoising, so the outputs of tedana would not be cropped. But then, if the ICA and PCA are not run on the full data, then we wouldn’t have components that cover those initial TRs . I’m not sure how to deal with that.
I also vaguely recall that T2*/S0 were once estimated on the non-steady state volumes specifically, so would we want to remove those volumes before that step in the workflow?
Agree on removing them, I’d imagine they could cause trouble with the dimensionality reduction steps. With SIEMENS scanners the true dummy volumes are not saved, but there is still a bit of non-steady state remaining at the beginning.
Is there not a way to specify volumes to be dropped in processing for fmriprep? Would make sense to me to just drop them right at the beginning of processing so that they aren’t causing trouble at any stage later (I, of course, have AFNI brain and this would be the approach there).
I think the T2*/S0 estimation on non-steady state isn’t a huge concern, given the relative quantities of data, say 2 or 3 volumes to 100+ I would be inclined to trust measures from the bulk of the timeseries more than those from a few points.
For the new parameter - it could be possible to keep steady state for steps 1 and 2, then discard them for PCA/ICA/comp selection. Then, in opt com they go back in. For denoising, the two or three bad volumes could be temporarily cut out - then denoise timeseries → then add them back in (denoising shouldn’t substantially alter the mean). I don’t like this idea really, its overly complicated, but it could help with an edge case like this.
Welcome @sjshim and thank you for asking this question.
These volumes definitely should not go into tedana. I think adding a --skipvols option might be a bit tricky since we can’t remove volumes for the ICA and then add them back in for the denoising step. That means we’d either be keeping them at the beginning of the volume untouched or using tedana to remove those volumes.
My inclination is that they should be removed as part of the preprocessing pipeline, not tedana because, for the sake of reproducibility, you’d want your preprocessing pipeline and not some cog in the pipeline to keep track of when a volume is removed and how that affects other steps in the pipeline.
T1 has been estimated from the non-steady state volumes. See: Bodurka, J., Ye, F., Petridou, N., Murphy, K. & Bandettini, P. A. Mapping the MRI voxel volume in which thermal noise matches physiological noise–implications for fMRI. Neuroimage 34, 542–9 (2007)
It might be possible to use the non-steady state volumes and multi-echo information to get a T2* estimate, and I vaguely remember reading something, but can’t remember the reference right now.
fMRIPrep identifies these volumes and accounts for them throughout the preprocessing without removing them from the time series completely. I believe it may use them to create the reference volume it uses for coregistration, but don’t quote me on that. It also notes them in the confounds file it generates.
@tsalo’s description of what fMRIPrep does is right in every point, and his suggestion of dropping the volumes, further processing, and then re-adding mirrors what we do in the very few cases (I think only ICA-AROMA denoising) where a preprocessing step needs to skip dummy volumes and also produces a BOLD series (instead of a confound time series, as in CompCor) as output. Schematically:
| dummies | remainder |
v v
v process
v v
| dummies | processed remainder |
The main reasons we have for insisting on keeping these dummies is:
You may disagree with our automated non-steady-state detection.
If we drop dummy scans, then the BOLD outputs no longer align with the events.tsv in the raw dataset. This already kind of happens with slice-timing correction, and we’ve started adding a StartTime metadata parameter to the output. Now we just need to get L1 models to respect that…
It makes sense that tedana doesn’t want to dive down the same rabbit hole.
I think in the short term it makes sense for users to pre-truncate and modify their events.tsv. Probably between fMRIPrep and tedana, so we can use the dummy scans to generate a better reference volume. In the long term, I think it probably makes sense for fMRIPrep to bite the bullet and allow users to drop dummy scans from both their BOLD files and confounds timeseries.