Hi @abore ,
Thanks a lot for your reply! I follow @effigies and your advice and use the tree command to get the data frame as bellow:
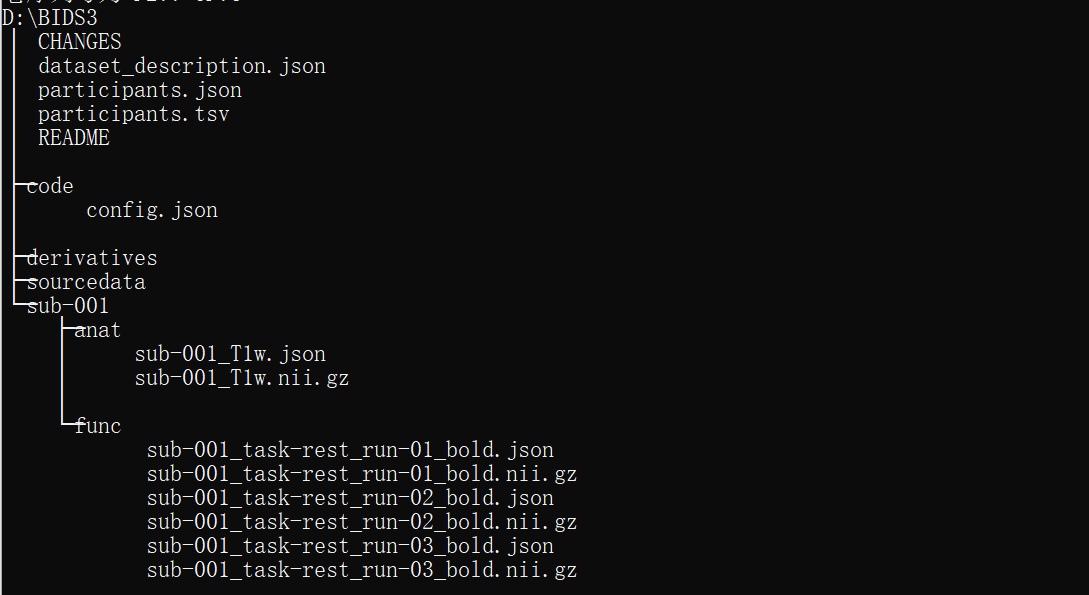
The command on fmriprep run well and there is no error. But the results is not what I expected, since I use the multi-echo data and I thought that the fmriprep-docker will automatically combine these three echos but actually it’s not. So there must be something that I need to correct and I am trying to figure it out.