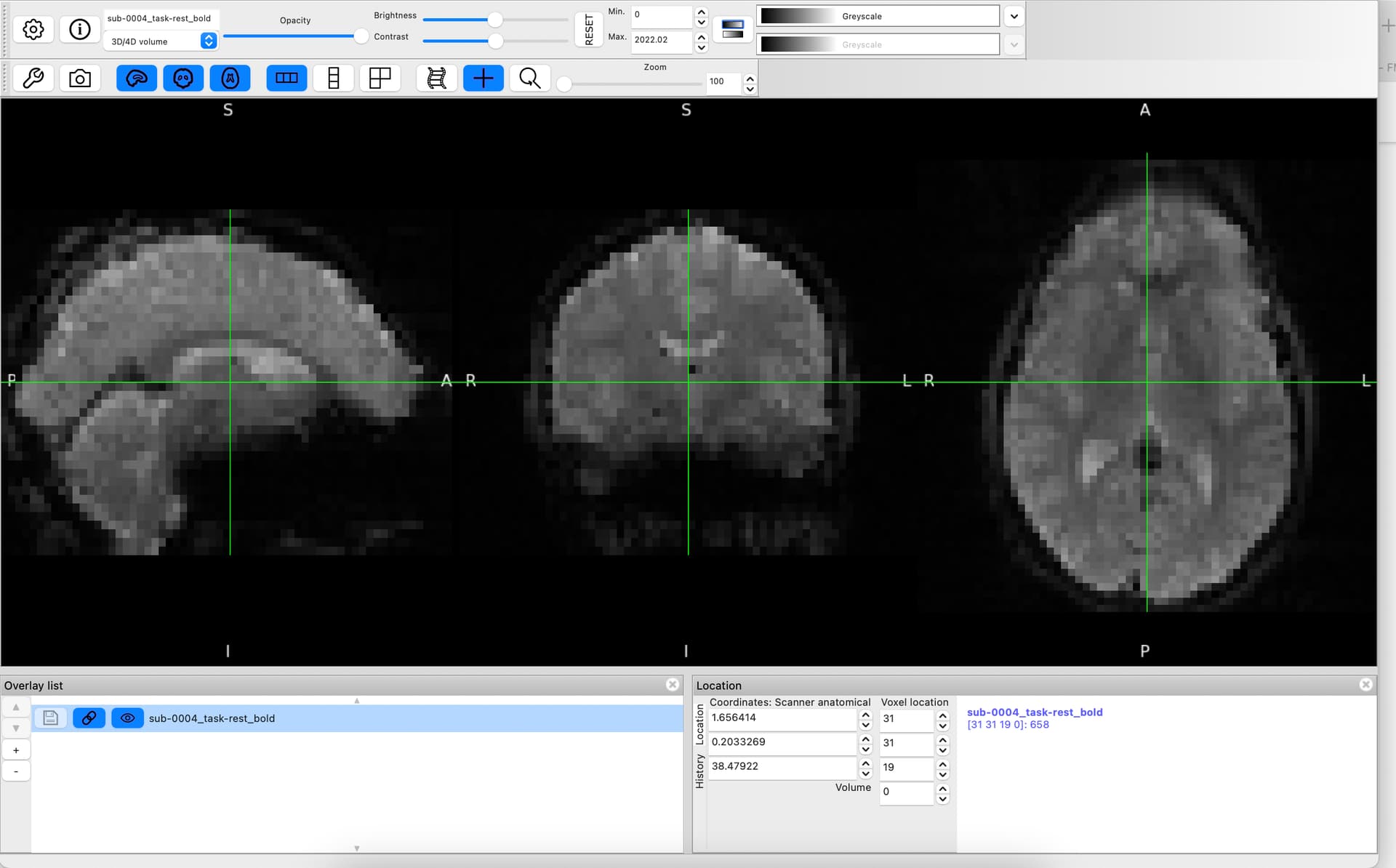
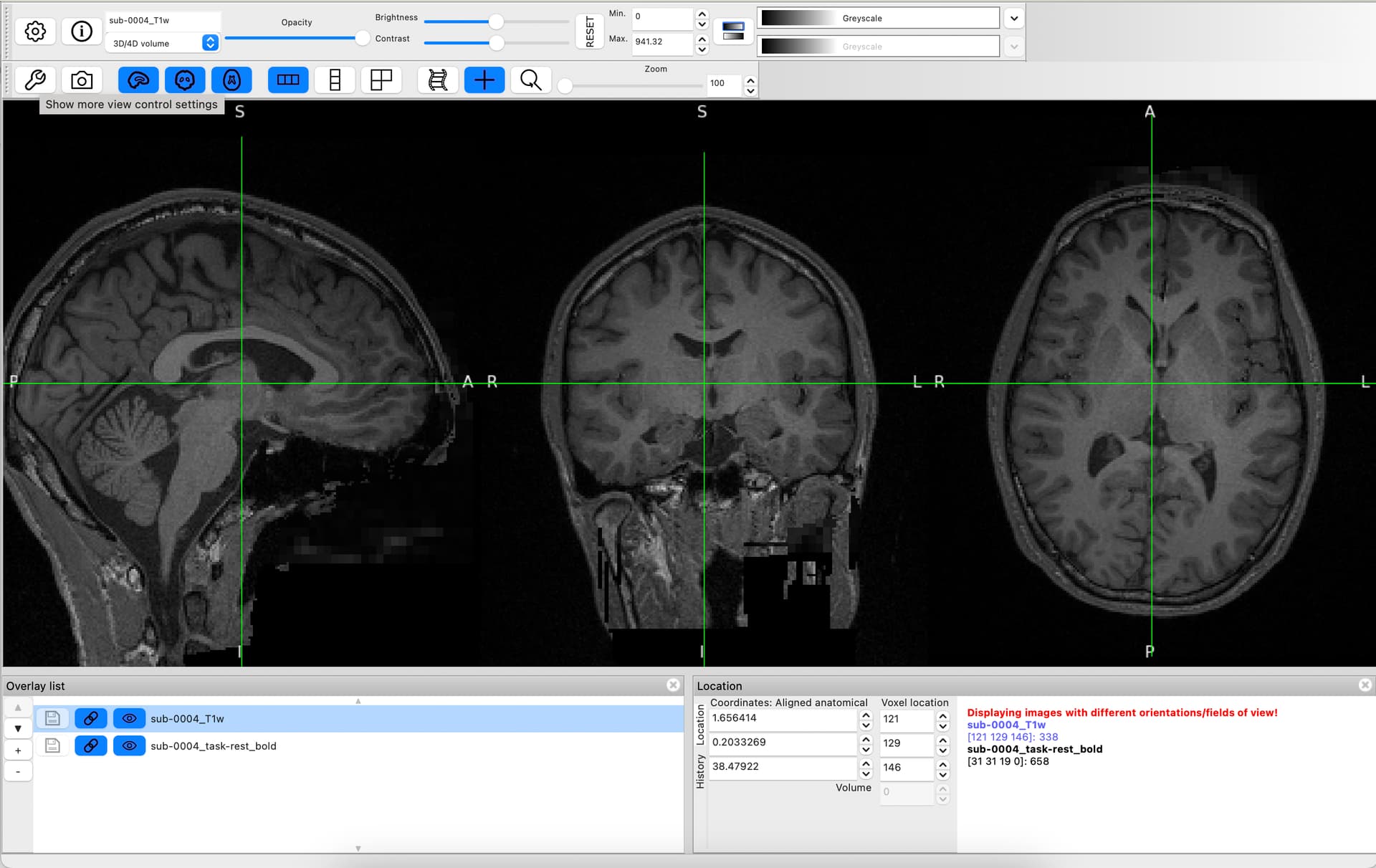
I am hoping that someone can help me with the fmriprep preprocessing of my data that contains resting-state fMRI EPI images with number of volumes (.nii) and defaced T1-weighted structural image (.nii).
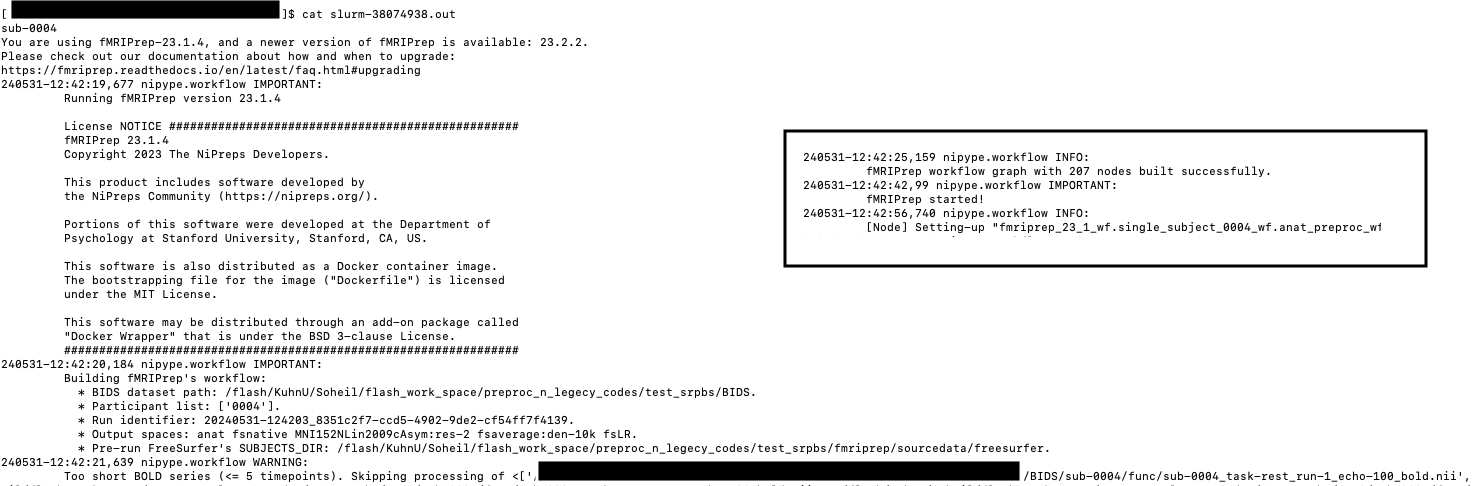
When I run the fmriprep (at present, just a single subject), it discards all the rs-fMRI related volumes (240 in total), as shown in the following figure.
Hi @Soheil , The first thing is to check that your data is on BIDS format. Is that the case?
To use FMRIPREP, do you have access of a High Performance Computing Cluster (HPC)? OR do you plan to use it on your personal computer, with Docker for instance?
I haven’t converted them. They were in their current format when I downloaded them. I have never had any issues with ‘DICOM’ formatted files. This is a first time that I am using multi-volume files.
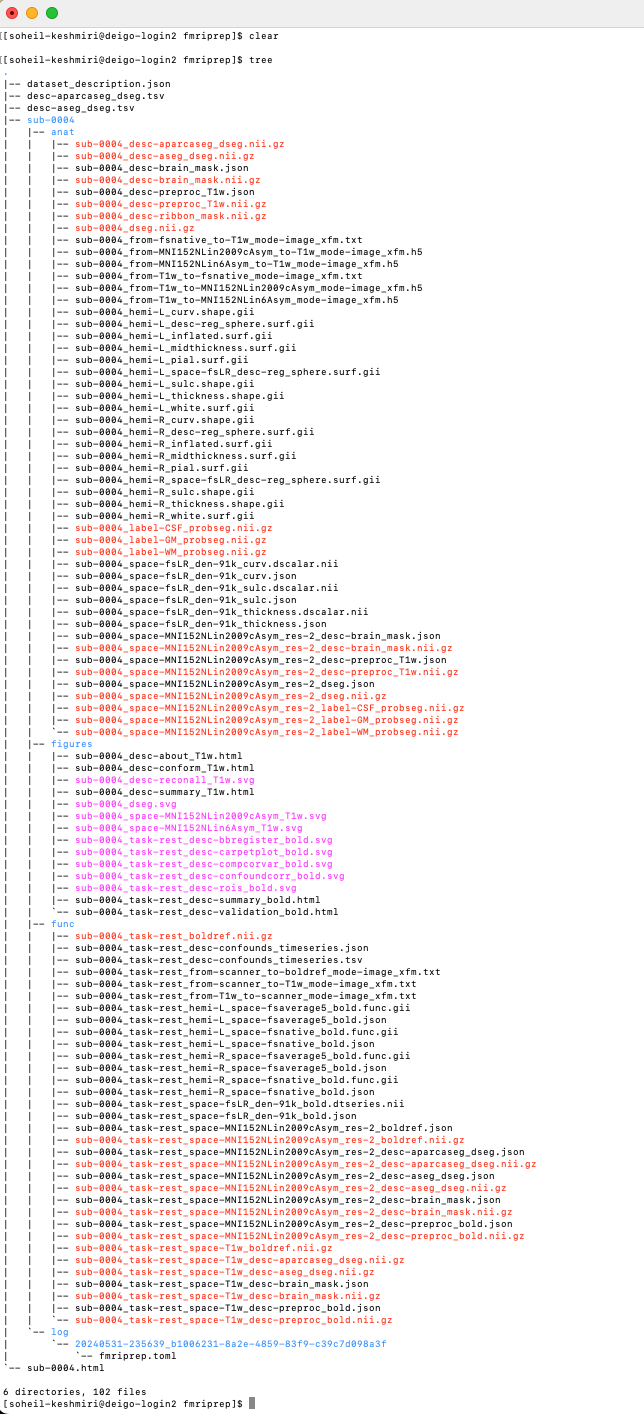
I see. Which database is the participant that you try to preprocess from? I see that the database 4 is already in BIDS format. Are you able to read this nifti file with a neuroimaging viewer such as FSLeyes, AFNI or SPM?
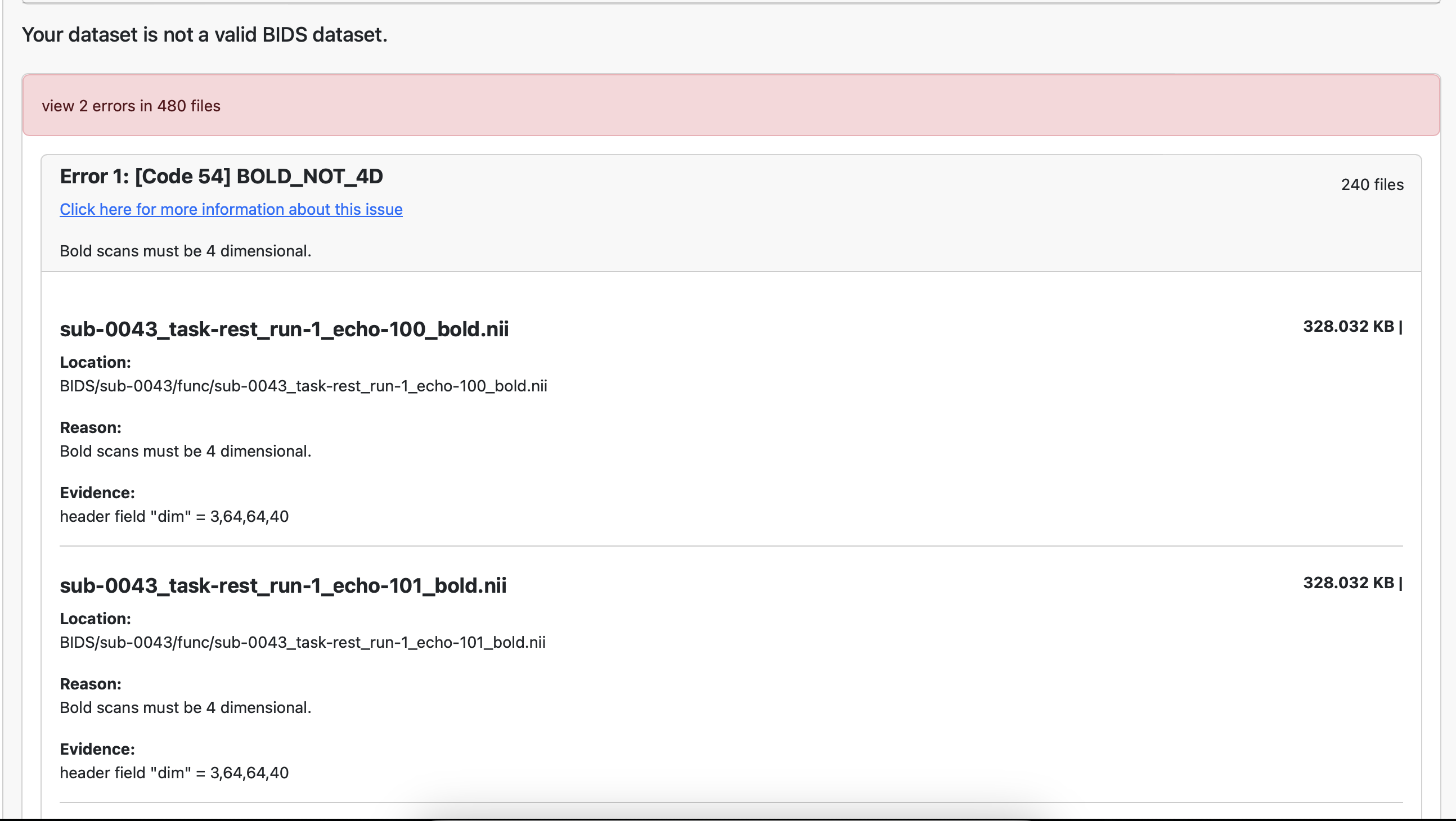
The validator’s message continues, covering all 240 .nii files. Please let me know if you would rather like to see the entire messages/tree and I will send them in multiple screenshots.
The files did not come with a .json file. I prepared them using the minimal information below.
The content of rs-fMRI BOLD .json file (same repeated for the remainder of 240 files).
{“RepetitionTime”: 2.5, “TaskName”: “rest”}
Please note that the above TR is associated with one of the site (i.e., the site which this single subject comes from).
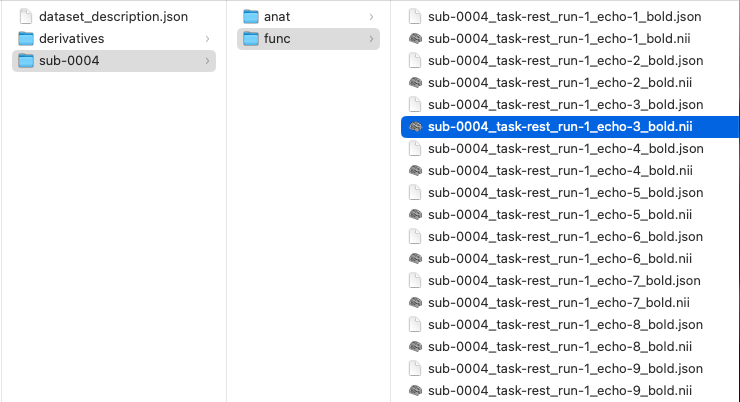
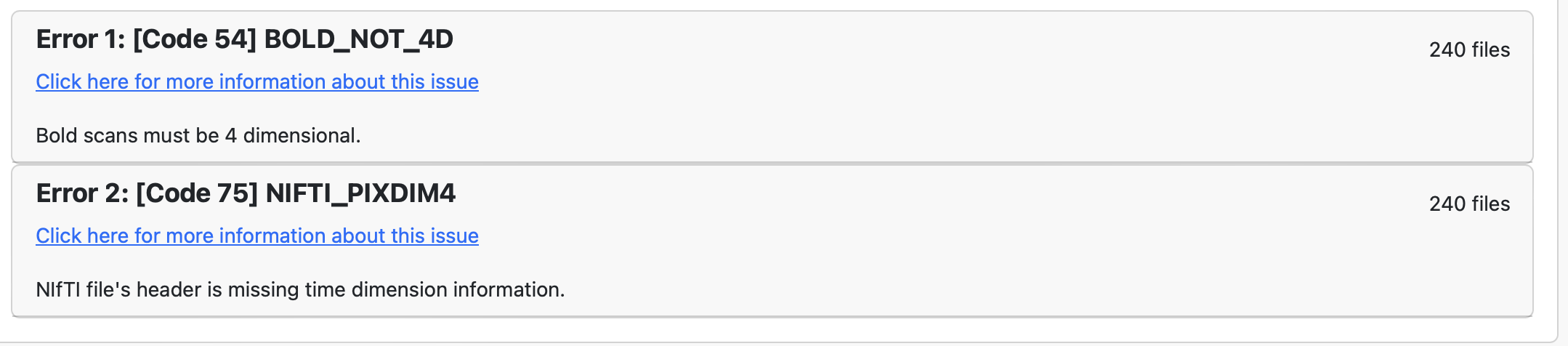
The error is pretty clear: BOLD images are 4D. If each file is a single volume, then they are not in BIDS format. The use of echo- here is a misuse of the entity. Echos are not TRs, but recordings of the same TRs at different echo times.
Combining is pretty quick with nibabel (just written, not tested):
import json
import numpy as np
import nibabel as nb
file_fmt = 'sub-{subject}_task-rest_run-1_echo-{vol}_bold.{ext}'
subject = '0004'
nvols = 240
with open(file_fmt.format(subject=subject, vol=1, ext='json') as fobj:
sidecar = json.load(fobj)
TR = sidecar['RepetitionTime']
images = [nb.load(file_fmt.format(subject=subject, vol=vol, ext='nii')) for vol in range(1, nvols + 1)]
data = [img.dataobj for img in images]
header = images[0].header
zooms = header.get_zooms()[:3] + (TR,)
out_img = nb.Nifti1Image(np.stack(data), None, header)
out_img.header.set_zooms(zooms)
fixed_fmt = 'sub-{subject}_task-rest_run-1_bold.{ext}'
out_img.to_filename(fixed_fmt.format(subject=subject, ext='nii.gz'))
with open(fixed_fmt.format(subject=subject, ext='json'), 'w') as fobj:
json.dump(sidecar, fobj)
May need minor fixups, and you should look at the results carefully to make sure you trust them. You could also use tools like fslmerge and fsledithd to do all this.
Dear @effigies thank you very much for your kind note. I will try the options you advised. I will reach out again to share if I succeeded or I would need some further assistance.
Further to these, I have also applied the post-processing (i.e., normalization, confound regression, bandpass filtering, etc.) on the fmriprep output (rs-fMRI). It all went well.
Once again, thank you very much for your time and invaluable assistance.
First beer on me, if and when by any chance encounter we cross each others’ path somewhere than Internet!