I have an experiment that scans participants on two dates (2 sessions) with 4 runs in each session. I want to derive trial-wise beta-estimates based on the LS-S approach from this paper.
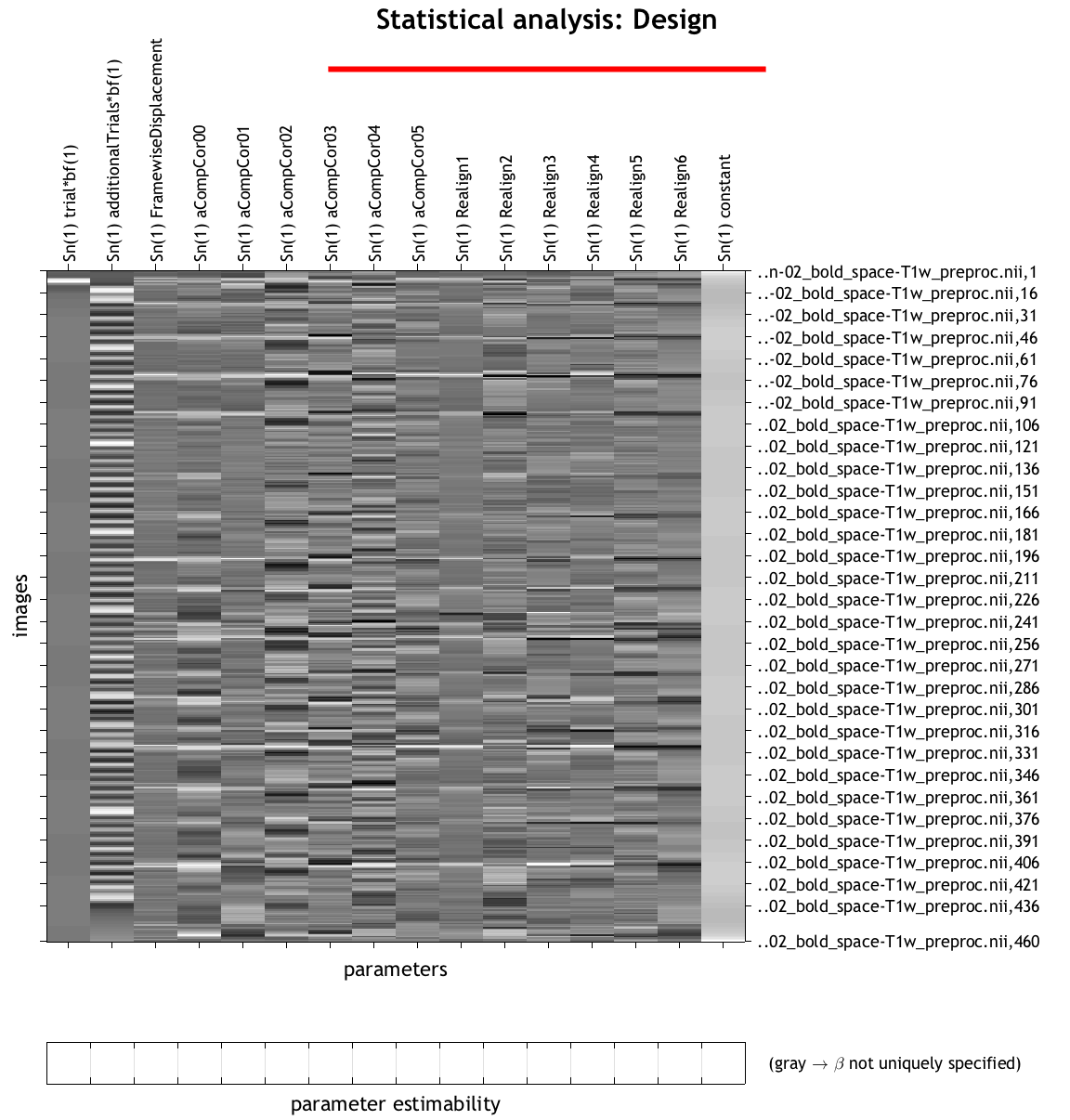
So I set up a GLM for each trial with (i) one condition for the current trial and (ii) another condition that includes all the other trials. Just for one run, the design matrix looks as follows:
So you can see the one trial in column one and all the other trials in column two. So far so good.
My problem now arises as I want to include the other runs and sessions in this GLM too, so in total 8 runs in one GLM for one trial. This means that the condition in column one will be empty for all the other runs in which the trial does not happen, i.e. the onset and duration vector is empty. SPM will not let me pass empty onsets in the model specification (I am using nipype).
Has anybody come across a similar problem? Is it possible to have different conditions for each session? Currently I also receive an error if I try to do this, but it might be my error.
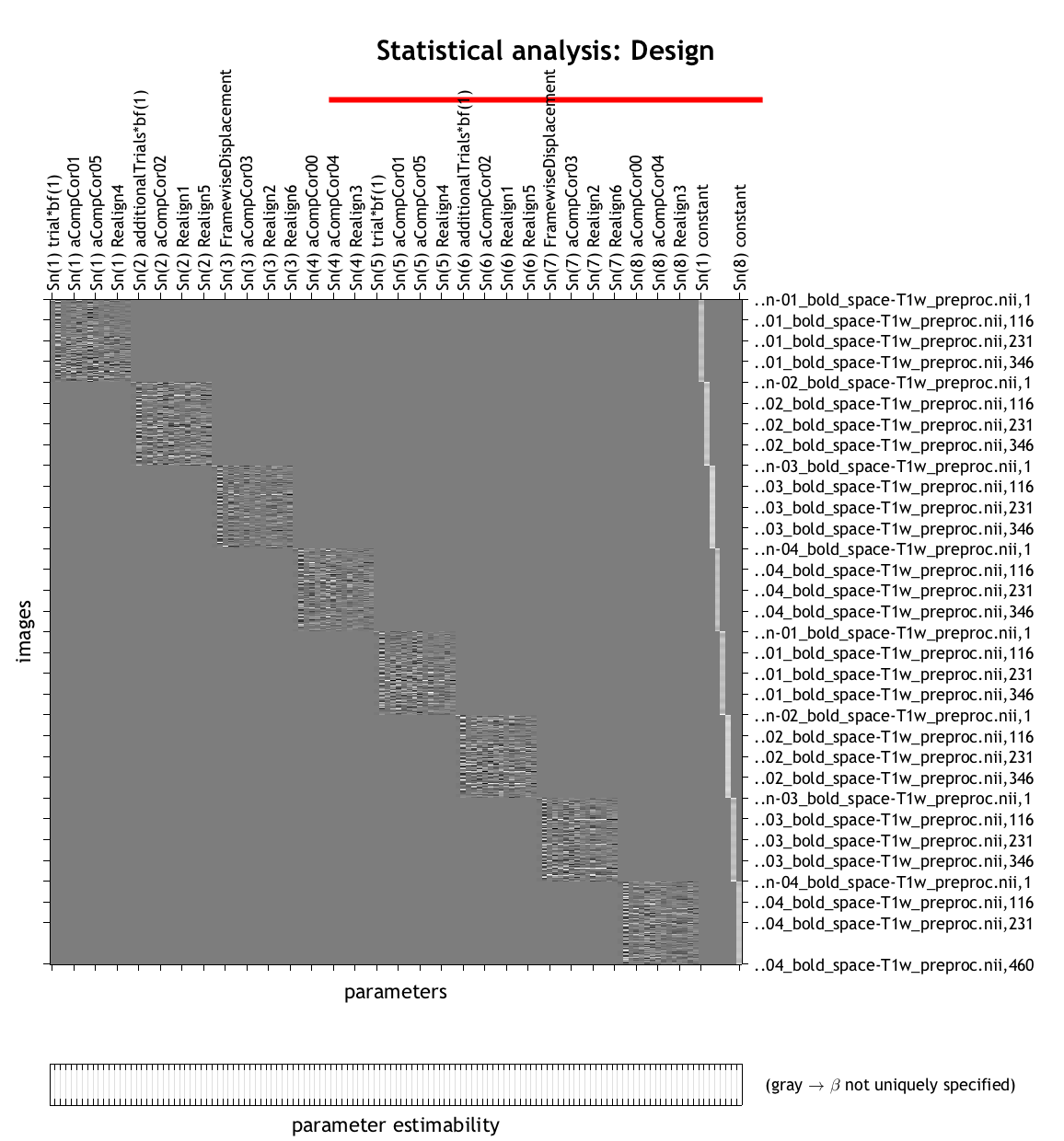
For reference: this is what the design matrix should look like with 8 runs:
So for session 1, run 1 and trial 1, the first column of run 1 would include one onset, but the other runs would not have any onset for that condition.
When doing LSS, I believe that you would want to take the single trial’s beta map from each trial-specific model and then concatenate those into a 4D time series for analysis (e.g., ROI-to-ROI functional connectivity analysis). At least, that’s how I’ve used it in the past. If that’s the case, then I don’t think there’s any reason to model additional runs or sessions in your GLM. Including the other runs in the model won’t impact the betas for the single-trial condition in the first run, so unless you want to run contrasts across runs (which I don’t believe is the way to go), you don’t gain anything from including those runs in each model. Does that make sense?
Also, if you have multiple conditions (I only see “additionalTrials”), I think that you would want to model those as separate regressors from the condition you’re pulling trials out of, based on the updated version of LSS described in the followup to the paper you cited.
When doing LSS, I believe that you would want to take the single trial’s beta map from each trial-specific model and then concatenate those into a 4D time series for analysis (e.g., ROI-to-ROI functional connectivity analysis).
That is how I understood the approach as well.
Including the other runs in the model won’t impact the betas for the single-trial condition in the first run, so unless you want to run contrasts across runs (which I don’t believe is the way to go), you don’t gain anything from including those runs in each model. Does that make sense?
I don’t want to run contrasts across runs. In the end, I would like to decode based on the beta images. So I do have trials of the same condition across all sessions (and runs). I thought that this is the reason why I should include all sessions (and runs) in the trial-specific GLM. Could you please explain in more detail why the betas for the single-trial-condition will not be impacted?
Also, if you have multiple conditions (I only see “additionalTrials”), I think that you would want to model those as separate regressors from the condition you’re pulling trials out of, based on the updated version of LSS described in the followup to the paper you cited.
It’s just how your design matrix is set up. Each condition has its own column associated with a specific run (i.e., the design matrix has zeros in the rows associated with volumes in other runs), so the beta map associated with that column will be independent of the ones for the same condition in different runs. It’s only in computing contrasts that the betas from different runs are combined. Now, if you concatenated your data in your design matrix (like I think one would do for a PPI, though I could be wrong), then you’d have one column for each condition, across runs. In that case, the beta values for each condition would definitely be impacted by which runs are included, and you’d get one beta map for each condition. In the standard case, though, you get one beta map for each condition in each run, so there is one map (e.g., beta_001.nii) for condition 1 in run 1, one for condition 1 in run 2 (beta_017.nii), etc. The values in the first map are determined by the data just in run 1. Some data (e.g., the ResMS map) is going to be impacted by whether multiple runs are included in the GLM, but I fairly certain that the betas won’t be.
As a side note, in case it might be helpful, in the past when I’ve run LSS models, I did split it up by run to run single-trial, within-run models. You can see here (in MATLAB) how the code loops through the individual runs in a standard multi-run GLM to create the LSS models. I don’t know how NiBetaSeries does it, but I assume that it runs the single-trial models with only one run at a time (thought probably not with SPM).