Hello!
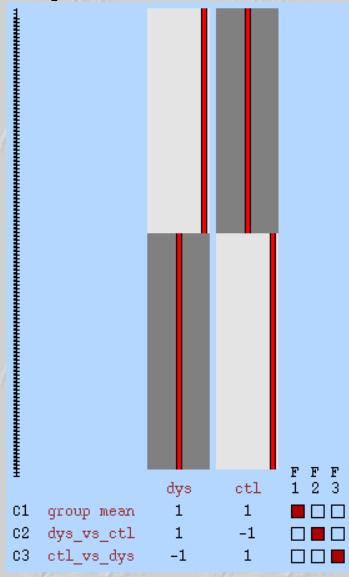
I am analyzing two different fMRI datasets one on dyslexia in adults (morphosem) and one in dyslexia in children (dyschildren). They both have control subjects. The children are aged 8 to 9 years old and the adults are all university students of similar age. I have already preprocessed and ran 1st level analysis the data for all 40 subjects (morphosem) and 41 subjects (dyschildren) in each dataset in FSL. I ran 2nd level analysis for dyschildren which has 41 subjects and 3 runs using the following models:
I think we’d need a lot more information to provide guidance.
How many subjects per group
How preprocessing and first-level modeling was performed
Do the first level maps look reasonable
Nature of the task
This is unclear as it suggests that one group (dyschildren) has more subjects then the total number of subjects.
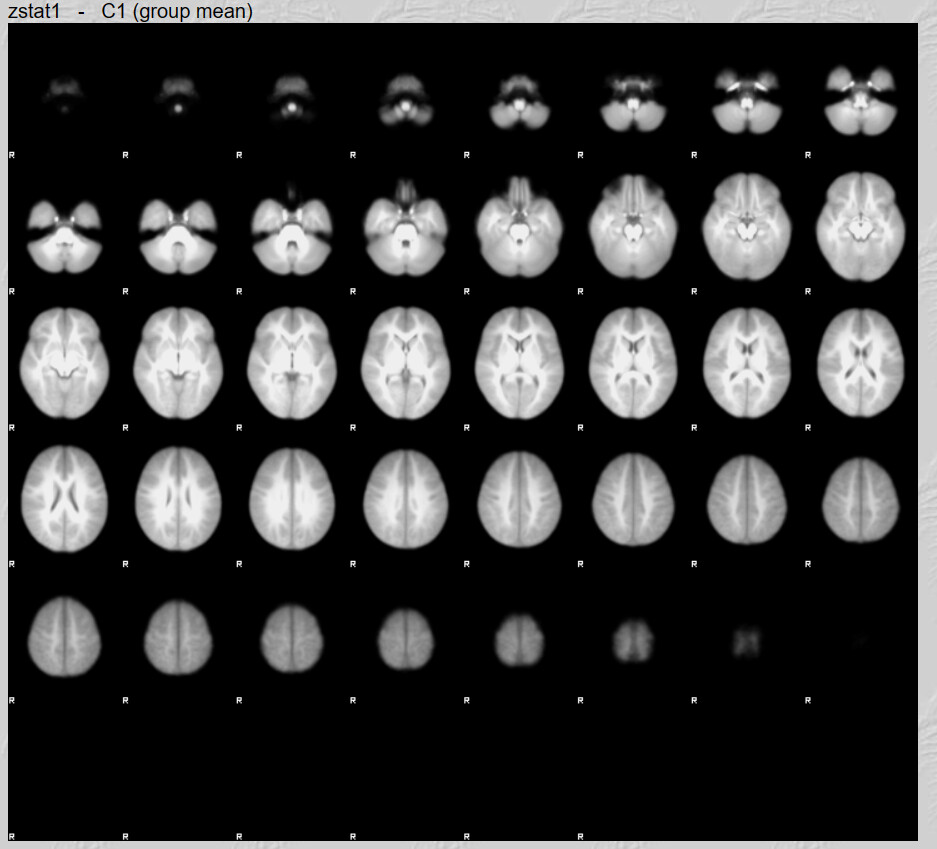
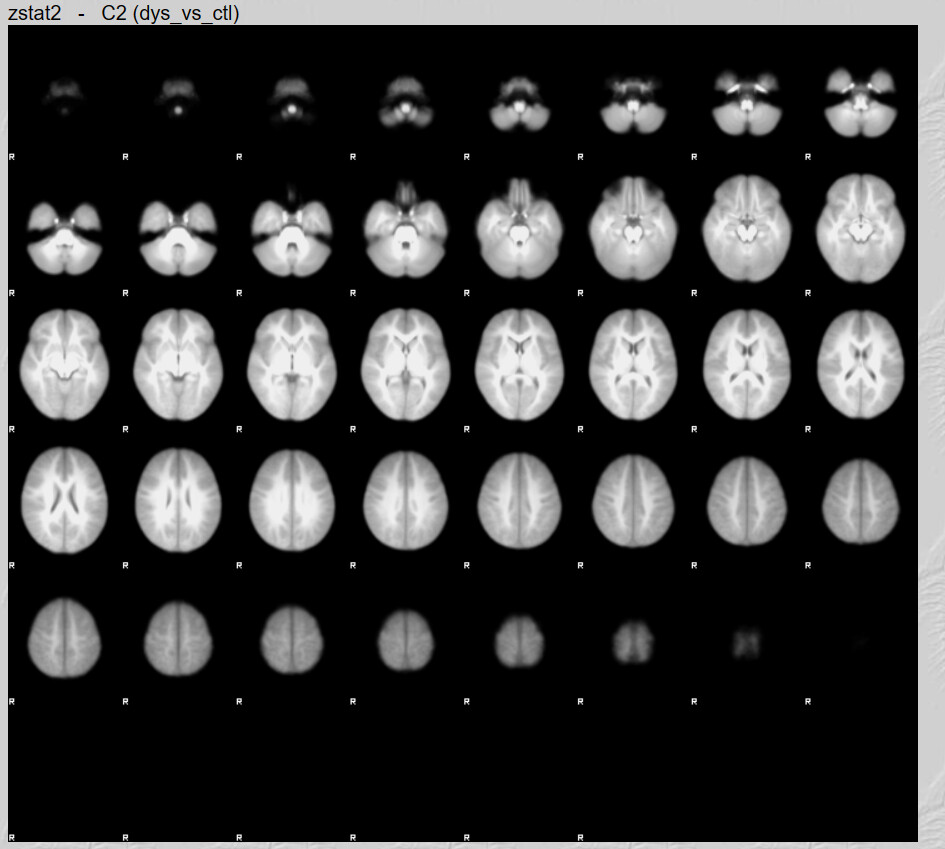
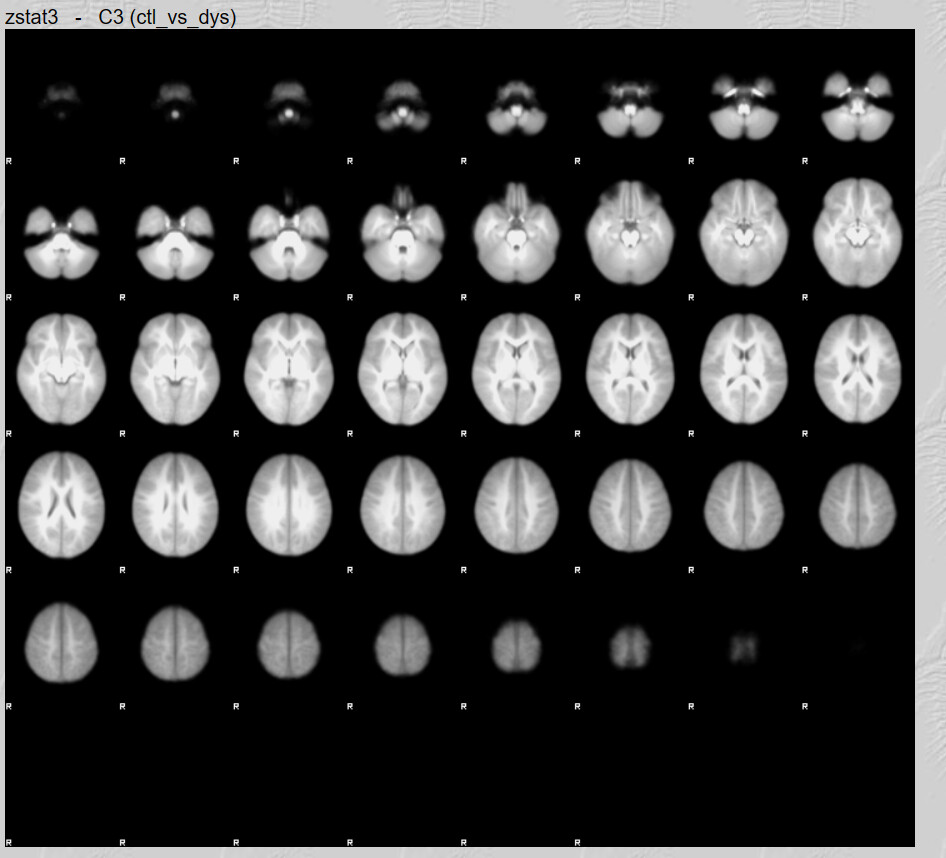
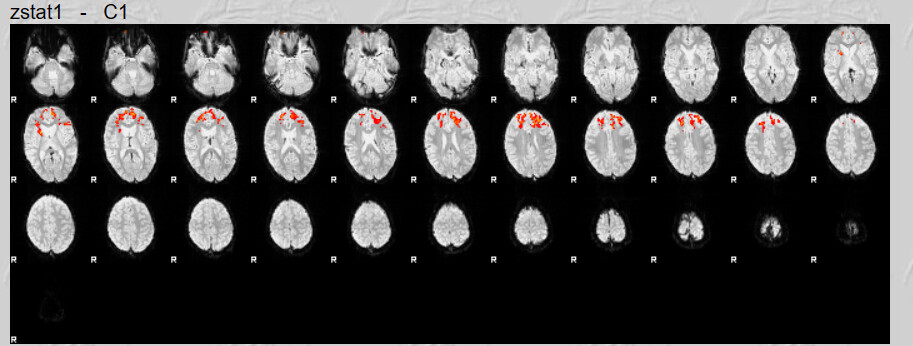
It is of course always possible that nothing survived thresholding (z>3.1 and cluster threshold of p<0.05). 40 participants in a group setting will not be an especially powerful analysis.
The task is event related. Here is the exact description from the OpenNeuro page: “Stimuli consisted of 60 words and 60 matched pseudohomophones of three to eight letters. Each stimulus was presented alone in white on a black background for 3s in an event-related design. After it disappeared, a fixation cross was displayed. The presentation of the fixation cross was jittered between 2000 and 6000 ms (M = 4000 ms). To prevent fatigue effects in children, stimuli were presented over three consecutive runs of 40 items each, separated by short breaks of 3-5 min. Children were instructed to read aloud the stimuli appearing on the screen.”
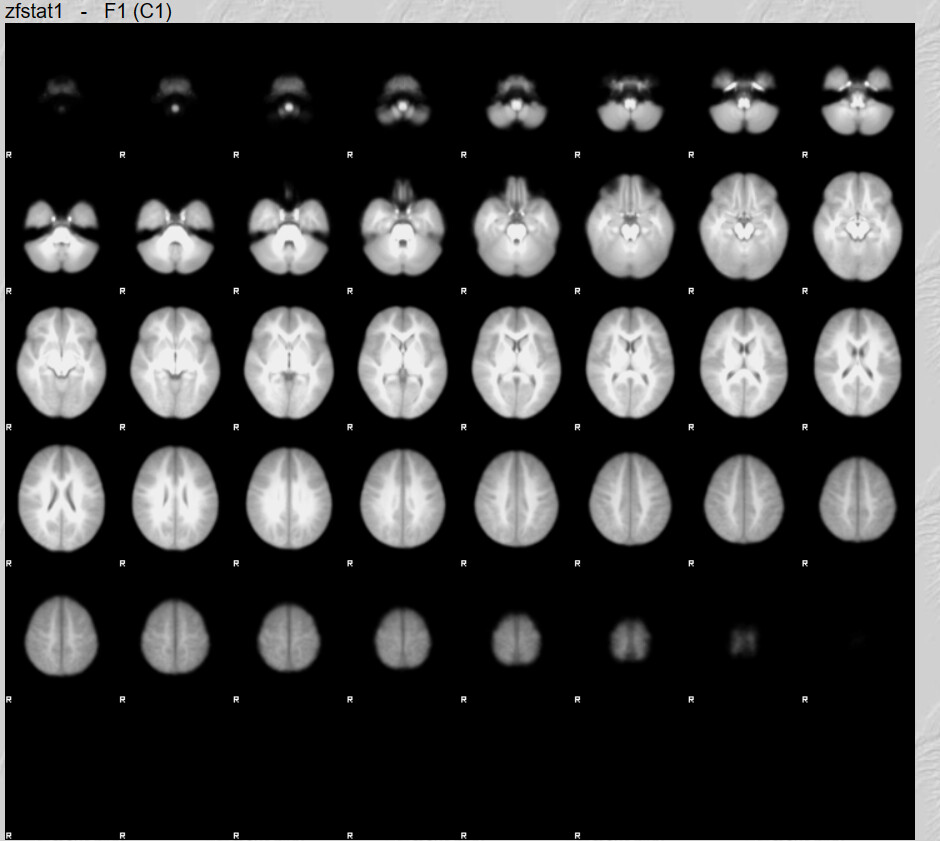
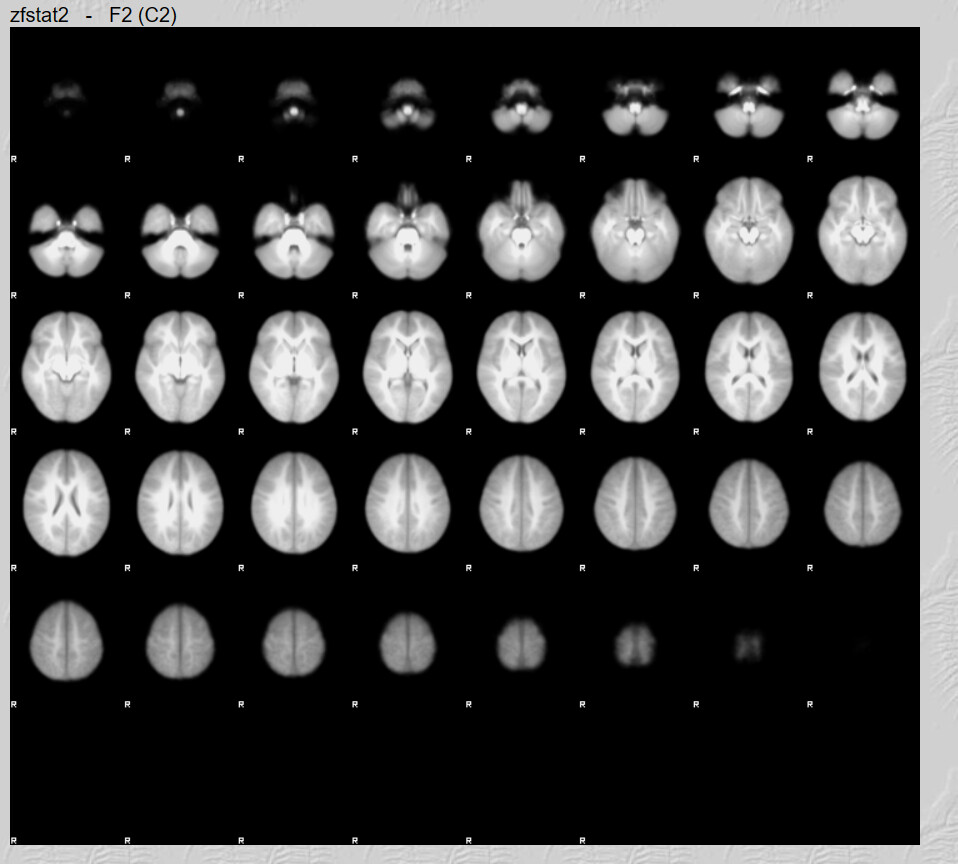
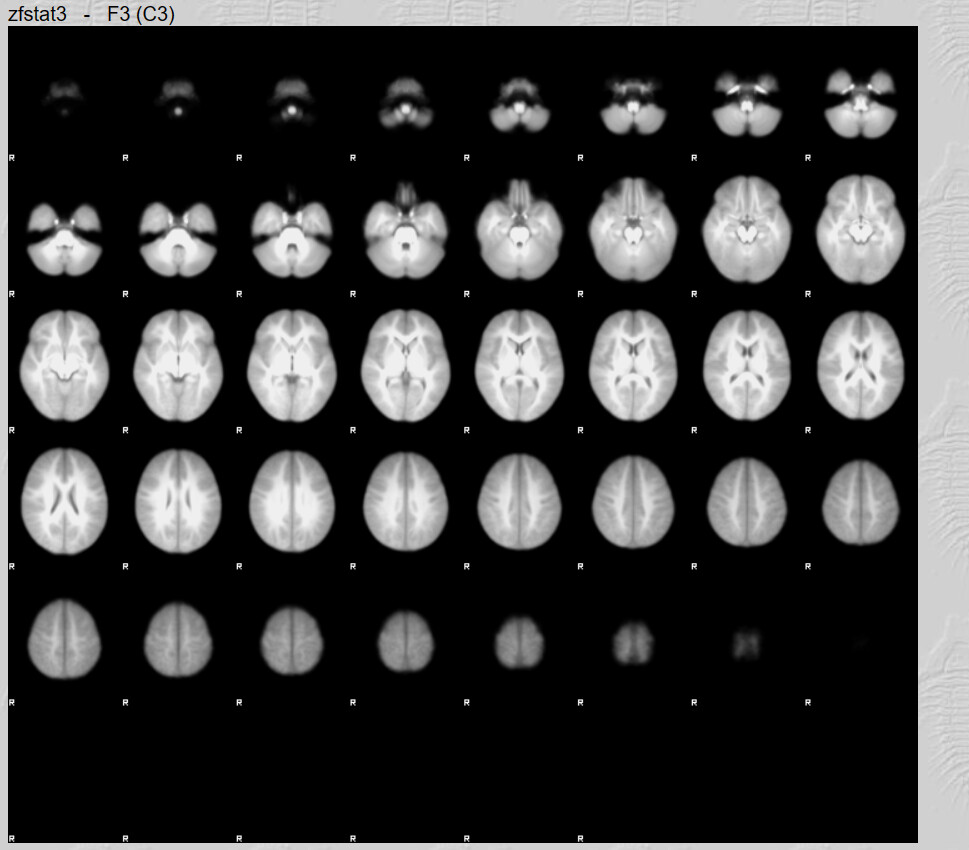
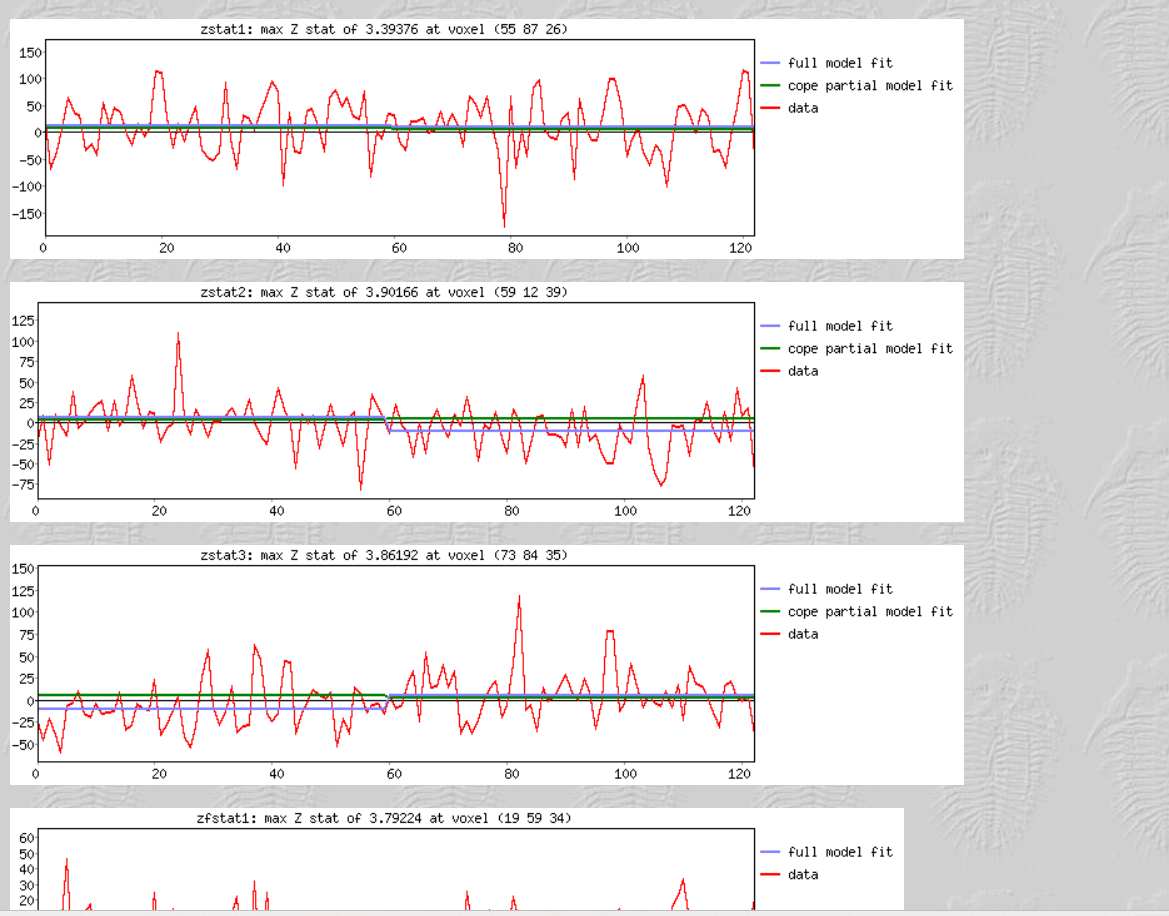
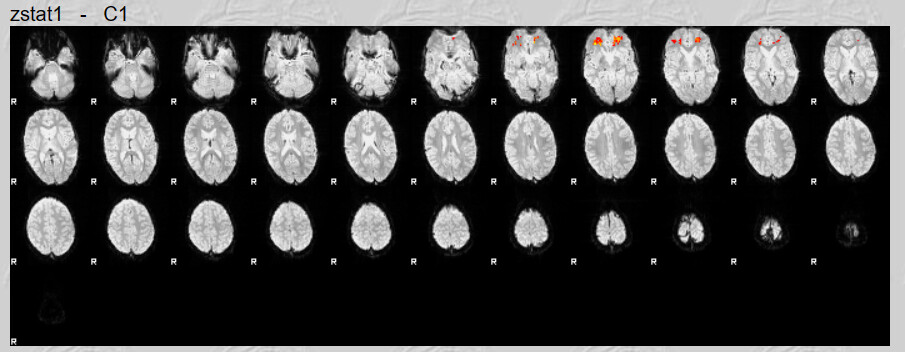
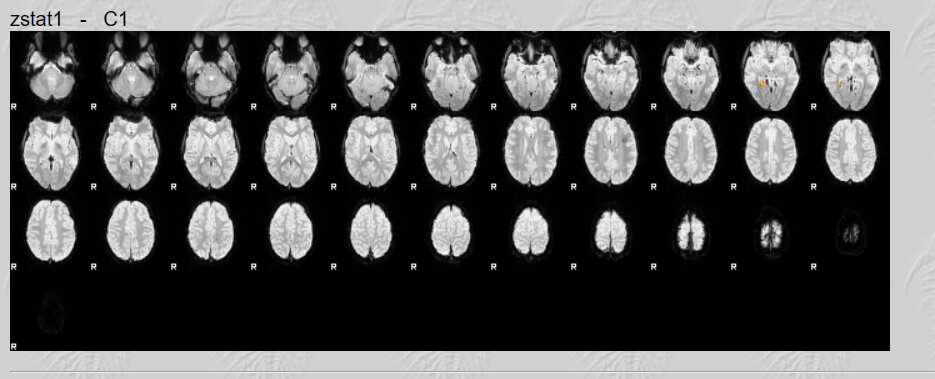
I do have one question, there are quite a lot of brain maps from the first run that don’t have any activation clusters. I believe this is what influenced the 2nd Level analysis results. Is not having any activation an error?
The steps you took. e.g., what regressors were used in your first-level model, were data smoothed at all, what was the contrast, etc
Hard to say without knowing how first-level models were made.
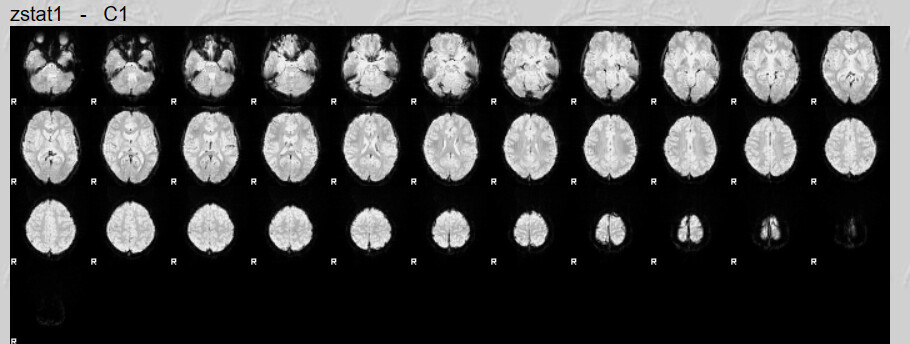
These brains look like they have a lot of anatomical warping near the front. If you can preprocess again with some form of susceptibility distortion correction (e.g., --use-syn-sdc in fMRIPrep) that might be helpful. Also I see a lot of frontal activation whereas reading is typically associated most strongly with with visual and left occiptotemporal activation. Knowing what contrast you used for first-level analyses would help decide if your maps are plausible.