I am working with fMRIprep preprocessed functional data and have encountered some questions I hope to get some insights on.
For the preprocessed functional file (sub-1001_task-Mult_run-01_space-MNI152NLin2009cAsym_desc-preproc_bold.nii.gz ), I aim to isolate gray matter signal by removing the CSF and WM components using a mask. The corresponding brain mask (sub-1001_task-Mult_run-01_space-MNI152NLin2009cAsym_desc-brain_mask.nii.gz ) seems to include the entire brain region. In the anat folder of the same subject, I found the probabilistic segmentation files for CSF, GM, and WM (e.g., sub-1001_space-MNI152NLin2009cAsym_label-CSF_probseg.nii.gz ). However, these anatomical segmentations differ in dimensions and resolution from the functional images. Do I have to resample these probability segmentations to the functional space, and are there any critical issues I need to be wary of that could lead to significant errors during this process?
I am going to do group-level analysis and after the minimal preprocess, should I select specified confounds for denoising based on each subject’s fmriprep report for every run? After individual subject denoising, are there additional denoising steps that need to be considered at the group level?
I think it depends on what software and functions you use. Some may do the resampling for you. But you probably don’t want to use the probseg masks. You can just use the dseg file and only use regions valued of 1. Remember that when resampling the dseg mask to use nearest neighbor interpolation since you are working with a discrete categorical mask.
You should use one denoising strategy for every participant. This does not mean every subject has the same number of regressors necessarily though. For example, subjects might have different number of motion outliers or acompcor components (if you use all components to explain 50% variance, for example).
This depends on what your research question is. Sometimes, age and sex are covariates that are used in 2nd–level modeling, as well as mean framewise displacement. But there’s not one single strategy that works for every analysis, and without knowing more about your analysis it is hard to recommend one.
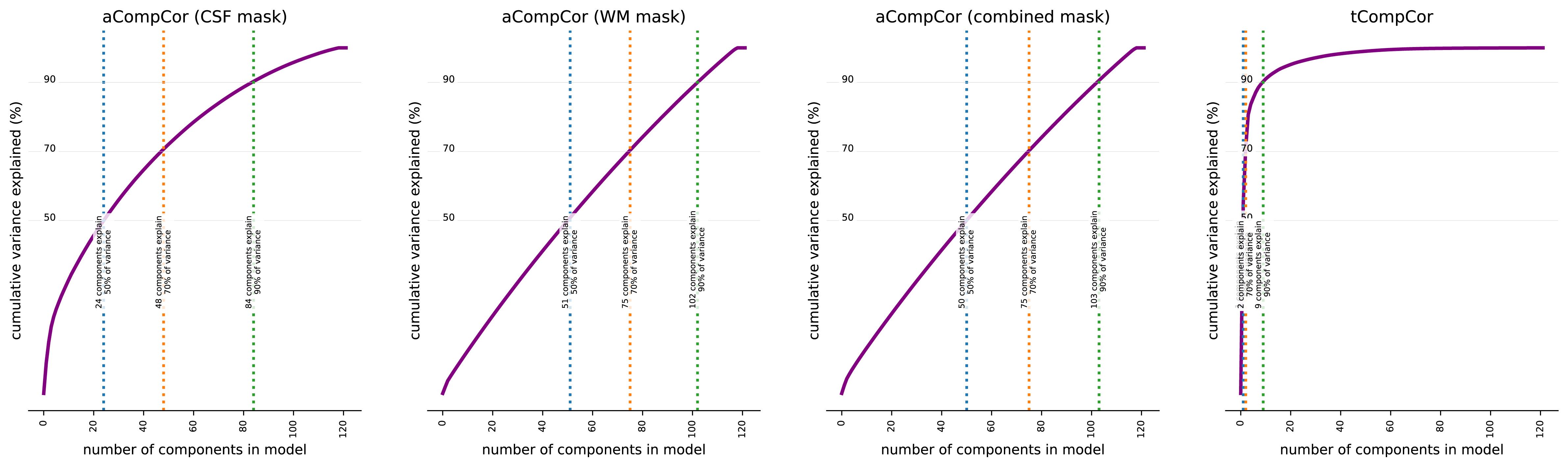
Based on your suggestions, I’ve decided to apply a consistent denoising strategy across all participants. This includes using all components necessary to explain 50% of the variance in aCompCor with a combined WM&CSF mask, employing all components to account for 50% of the variance in tCompCor, and incorporating 6 motion parameters for each participant. Does this approach sound appropriate?
Regarding my research, I’m exploring the semantic mapping between stimuli and BOLD signals, drawing inspiration from this study. Specifically, I’m fitting a regression model to map from embedding_size to num_voxels using parts of the BOLD signals and corresponding stimuli, where each stimulus is a paragraph of natural language with each word represented as a vector of embedding_size . The goal is to validate the effectiveness of this mapping on held-out signals. I wish to minimize differences among participants except for semantic features. Given this context, it seems mean framewise displacement might be a relevant measure. Would you recommend incorporating it, or do you have any other suggestions?
I wouldn’t use both tcompcor and acompcor together. I also don’t know anything about your data, sometimes a lot of components may make up the 50% variance explained, and if you have a low number of volumes, then you can be sacrificing a lot of temporal degrees of freedom in your GLM.
In regards to the second point, I would have to think more, I am not familiar with this method and I am not very well-versed in the neural semantic mapping literature.
Thank you very much!
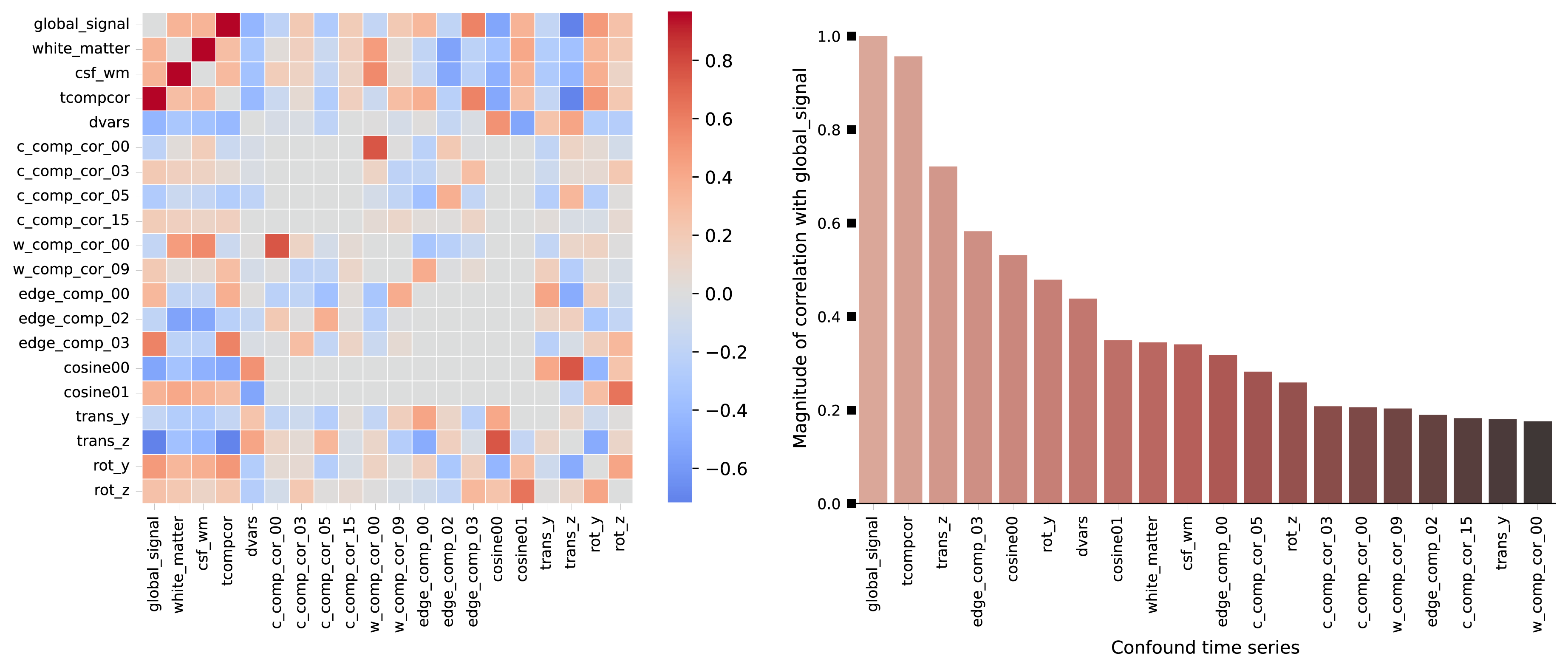
Could you please explain why it’s not recommended to use both tCompCor and aCompCor together? In my data, each series consists of 121 volumes. To account for 50% of the variance, only a few components from tCompCor are needed, whereas aCompCor requires significantly more components (approximately several dozen). I’ve uploaded two images regarding the confounds in the report. I’m not sure if they’re useful, but I hope they help.
Both strategies aim to address the same source of noise. Thus, using both in a model is redundant. aCompCor has been the more commonly used strategy in the field. In fact, I am not sure I have come across any paper having used tCompCor.
If you are worried about temporal degrees of freedom, you can also use a set number (e.g., the top 5) principal acompor components, which is another commonly used strategy.