I did my fMRIprep preprocessing again, using the newest version of fMRIprep; we decided to incorporate IC-Aroma and then I thought I would run the latest version. Now I am running into some issues with SDC.
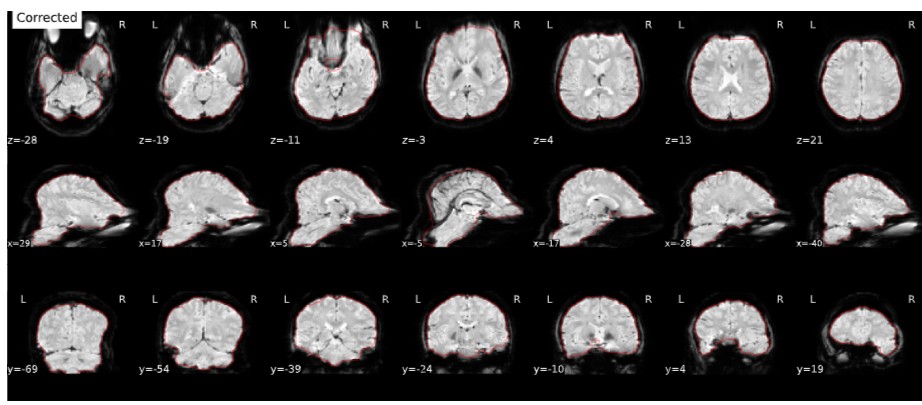
I have understood that the default SDC procedure has been changed with version 21 and it appears less robust for my data; the corrections after running version 22 are often very extreme, which causes issues with realignment with the T1 scan. This is in contrast to default SDC in the earlier version 20, which looks fine. I have this issue with multiple participants in my dataset, see attached figures below for one example participant.
Would you have any explanation and/or recommendation? Perhaps it is better to use the method of version 20 for my dataset?
In both cases I have not specified any particular method, i.e. I am using the “default”. This has changed with version 21 according to the online documentation
Looking at the reports in both instances, the following methods are mentioned
v22
A B0 nonuniformity map (or fieldmap) was estimated from the phase-drift map(s) measure with two consecutive GRE (gradient-recalled echo) acquisitions. The corresponding phase-map(s) were phase-unwrapped with prelude (FSL 6.0.5.1:57b01774). […] The estimated fieldmap was then aligned with rigid-registration to the target EPI (echo-planar imaging) reference run. The field coefficients were mapped on to the reference EPI using the transform. The BOLD reference was then co-registered to the T1w reference using bbregister (FreeSurfer) which implements boundary-based registration (Greve and Fischl 2009). Co-registration was configured with six degrees of freedom.
v20
A B0-nonuniformity map (or fieldmap) was estimated based on a phase-difference map calculated with a dual-echo GRE (gradient-recall echo) sequence, processed with a custom workflow of SDCFlows inspired by the epidewarp.fsl script and further improvements in HCP Pipelines (Glasser et al. 2013). The fieldmap was then co-registered to the target EPI (echo-planar imaging) reference run and converted to a displacements field map (amenable to registration tools such as ANTs) with FSL’s fugue and other SDCflows tools. Based on the estimated susceptibility distortion, a corrected EPI (echo-planar imaging) reference was calculated for a more accurate co-registration with the anatomical reference. The BOLD reference was then co-registered to the T1w reference using bbregister (FreeSurfer) which implements boundary-based registration (Greve and Fischl 2009). Co-registration was configured with six degrees of freedom.
Got it, I was wondering if this was either using a fieldmap or the SYN fieldmapless method. Looks like you have fieldmaps.
Have you tried the fieldmapless method? Might be worth giving it a shot (--use-syn-sdc, --ignore fieldmaps).
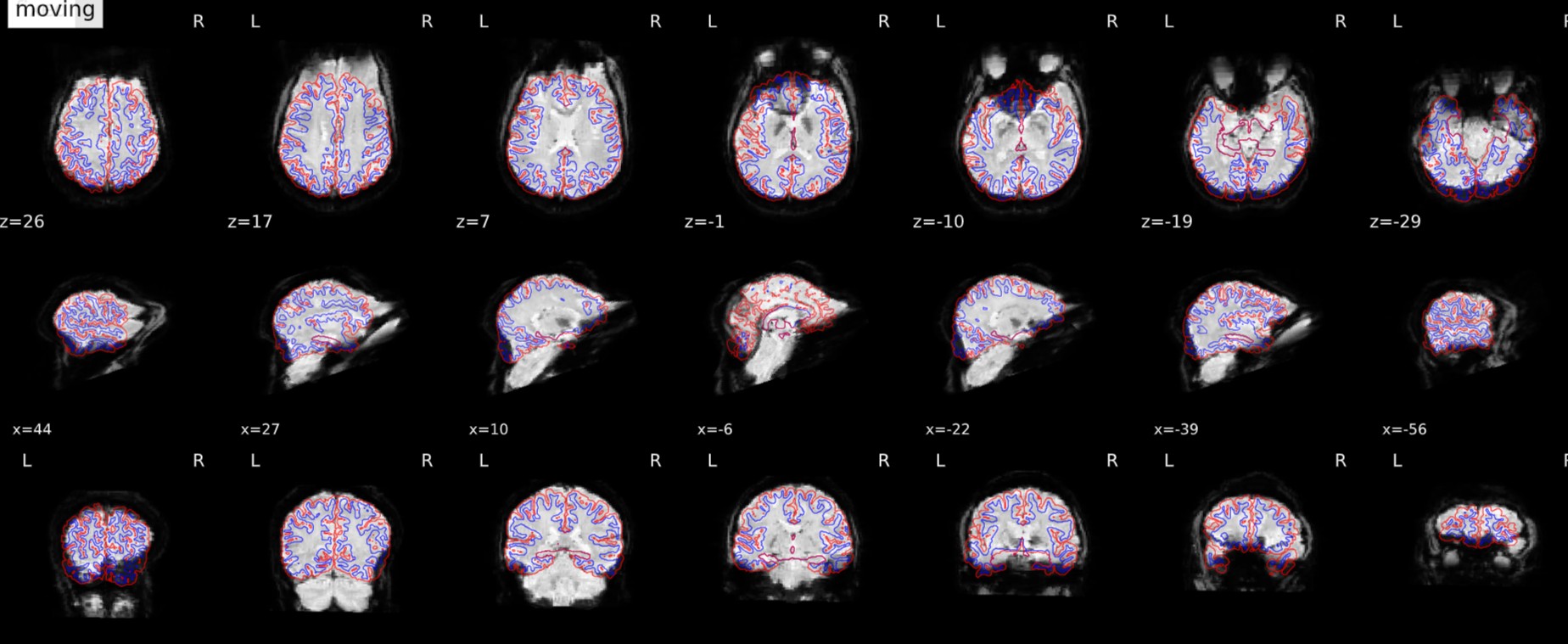
Yes, the images look weird, particularly looking at the saggital slices / middle row. But, they do line up well with the red outline (T1 boundary). Do your T1s look okay? Did you include FreeSurfer processing in your fMRIPrep command? If not, that could be worth trying too.
Ah yes, sorry indeed I forgot to mention that I have a fieldmap. I am just wondering, perhaps the v20 method would be better then instead of ignoring the fieldmaps?
If you click on the link of the original post you will find more figures (was only allowed to use one in the neurostar original post) If you look at this image below, you can see that the alignment with T1 is poor due to the heavy SDC corrections. This was not the case for v20 output (again, see link!)
Generally the quality of all scans is good (T1 and EPI) and I had no problems in preprocessing with fmriprep v20, not with any of my participant data.
I am not a user of the phase difference map method, so I can’t speak from my personal observations.
The report you are showing here, are they from the same subject? The contrast (and maybe the orientation) seems very different between the examples. How does the fieldmap look for the v22?
It is interesting to see that the method seems indeed to have change between v20 and v22, from epidewarp.fsl script to prelude. The method is also called differently, from Phase-difference (v20) to Phase drift (v22), whereas in the SDCFlows documentation, it is still referenced as Phase difference
Thanks for your reply! I have added the V22 fieldmap plot (which is now also different) tot the google drive (see original post)
I had noticed indeed the difference between phase-drift and phase-difference method (although I have little technical knowledge on the meaning / difference), but I assumed this is also what was changed with new implementation from v21, but apparently not… Why it chose other than the default is unclear to me.
Below my fMRIprep commands for both versions (for privacy, project and subject number are masked with ***), this is indeed the same participant, with same EPI, T1 and fieldmap
Hi,Laura. I met the same problems and I also have tested the preprocessing precedure of v20,v21,v22 ,field map based correction and field map less correction.
You can see it in my post.
For now, I think the v20 version of fMRIprep can give the most robust and reasonable result in the three versions. Otherwise field map-less correction give a more mild and no big error correction. And sometime, It’s better not to do correction than to do correction.