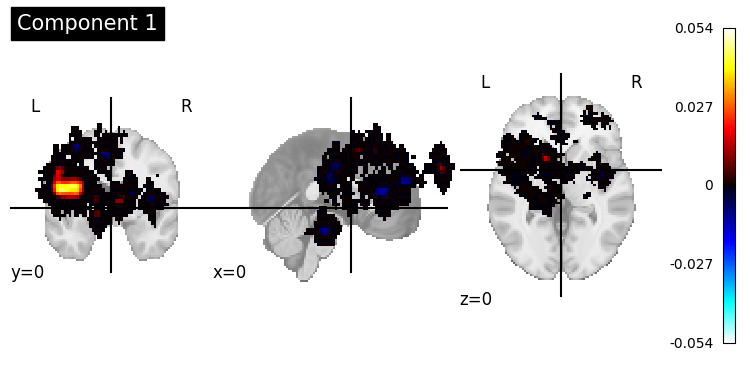
I am running ICA for data-driven parcellation, so I am testing different component numbers. I ran ICA with 50 components using Nilearn in Python, and this is what one of the components looks like. My question is: What are common causes of size differences between ICA components and mask data, and how can I resolve them? Additionally, what are the recommended preprocessing steps for fMRI data before applying ICA to ensure accurate component results? I have already completed the main preprocessing steps, including smoothing;
And plz any recommended sources to help me better understand how to analyze the results and address these issues?
I concatenated the preprocessed fMRI images from each group to continue running ICA
I switched to Nilearn on Colab due to resource limitations.
for the code i used this one :
# Load the 4D fMRI data
img_path = '/content/drive/MyDrive/all_subjects_data_4D.nii.gz'
fmri_img = nib.load(img_path)
print(fmri_img.shape) # To confirm the shape
# Define the number of components
n_components = 50
# Create an ICA object with appropriate parameters
ica = decomposition.CanICA(n_components=n_components,
smoothing_fwhm=6.0,
memory="nilearn_cache",
memory_level=2, # Proper memory management for caching
random_state=42,
n_init=10, # Multiple initializations for stability
threshold=3.0,
verbose=10) # Verbose output for detailed process logs
# Fit ICA
ica.fit(fmri_img)
# Get the ICA maps
components = ica.components_
# Compute the mask (if not already known)
mask_img = compute_epi_mask(img_path)
mask_data = mask_img.get_fdata().astype(bool)
# Prepare an array to hold the full-volume components
original_shape = fmri_img.shape[:3] # Spatial dimensions
full_volume_components = np.zeros((np.prod(original_shape), n_components))
# Map components back to full volume using the mask
for i, component in enumerate(components):
if component.size == mask_data.sum():
full_volume_components[mask_data.ravel(), i] = component
else:
print(f"Error: Component {i+1} size mismatch. Expected size {mask_data.sum()}, got {component.size}.")
# Reshape and save each component as a Nifti image
output_dir = '/content/drive/MyDrive/ICA50_output'
!mkdir -p {output_dir}
for i in range(n_components):
component_reshaped = np.reshape(full_volume_components[:, i], original_shape)
component_img = nib.Nifti1Image(component_reshaped, affine=fmri_img.affine)
nib.save(component_img, f'{output_dir}/component_{i+1}.nii.gz')
# Path to the component file
file_path = '/content/drive/MyDrive/ICA50_output/component_14.nii.gz'
# Load the NIfTI file
img = nib.load(file_path)
# Display the image
display = plotting.plot_stat_map(img, display_mode='ortho', title='Component 1', cut_coords=[0, 0, 0])
plotting.show()
The plot_stat_map will use on the default mni template image of nilearn if you do not specify the bg_img.
Try using one of your normalized subject T1 to see if at least overlap better there?
If you get similar visualisations as before, I would suggest double checking how you did the “normalizations” of your BOLD images. Am not an FSL expert so I am not sure how to help best.
For quick checks like this you may be better using fsleyes to view things.