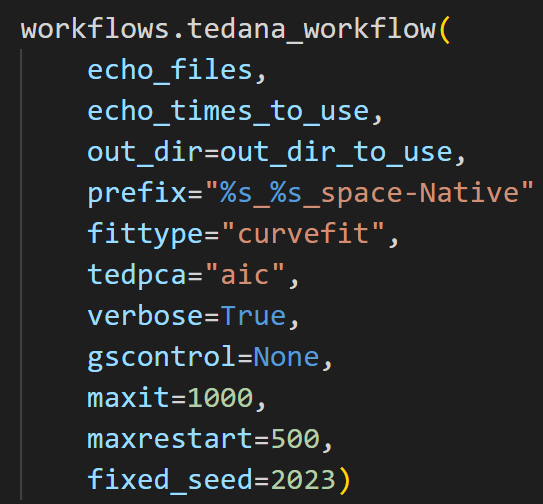
I am trying to denoise 2 movie-watching fmri runs using Tedana (latest version 23.0.1). However, in many cases ME-ICA fails to converge or does not find BOLD components or has very few components - depending on what options I select for --tedpca / --tree.
I am using fmriprep for preprocessing. The minimal preprocessed functional runs (with slice time correction and susceptibility distortion correction) are used as inputs to Tedana.
Any feedback or potential solutions would be very much appreciated
Hmm, this is a somewhat odd one - you have relatively large voxels, good spread of echo times and a reasonable TR, with a good duration for each run. The only thing I see that could be concerning is the 4x2 acceleration, which some may consider a bit high - but I don’t think that would be causing the issue.
187 components is a lot (from one example you showed that did not converge), so maybe the noise level is high and this is screwing up the PCA->ICA steps… This is related to an issue that we are currently working on, but no solutions yet. You also tried several methods there, so I’m trying to think of alternative explanations for the sake of having a consistent approach.
You mention slice timing and distortion correction in the context of minimal processing, I’m assuming that also includes motion correction as well?
Did the mask produced by tedana look ok? Or is it excluding too much brain?
Do the data look ok, if you watch a movie? As in, subjects didn’t move way too much and the image looks like a noisy brain more or less (and not just aliased ugly noise)? And the processing from fMRI prep looks like it worked well?
Regarding the error you see - I’m tagging @tsalo here, (and @handwerkerd for good measure) as I believe he worked a little on that error. I’m thinking the large number of components means that many are effectively just gaussian noise, and thus don’t really have much in the way of information. That would match with the convergence problem as well.
It looks like this may be another example of the PCA/ICA selection steps giving us trouble… I’ll think on it a bit more.
How many time points are in your data? There should almost always be less than 1/2 the number of components vs volumes and usually less than 1/3. A common reason the ICA does not converge is if it’s given too many PCA components and many of them are just Gaussian noise.
We are having issues with this PCA component selection step that seem to be with the algorithm we use and not specifically tedana. The --tedpca kundu and --tedpca kundu-stablize options use the echo properties of the components to decide which ones to retain for the ICA. This method was distributed with the original code and I conceptually like it, but it’s a bit brittle and hard to understand when/how it fails. The DICE warning you show is from that step.
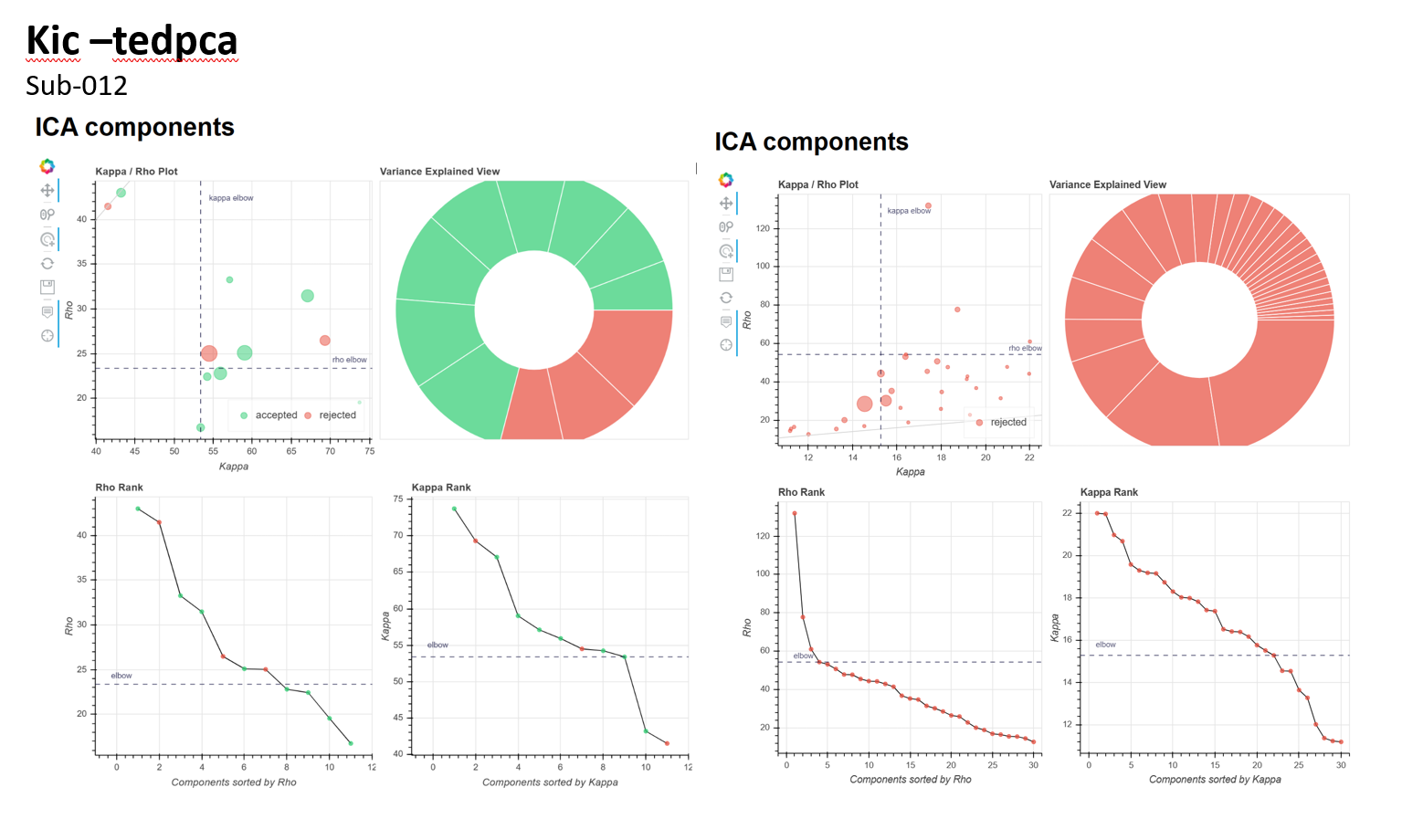
We have 3 other options that are all standard approaches based on cost functions. aic is the most liberal and will retain more components. kic is the moderate option, and mdl is the most conservative. you might want to try kic so see if using it solves that specific issue.
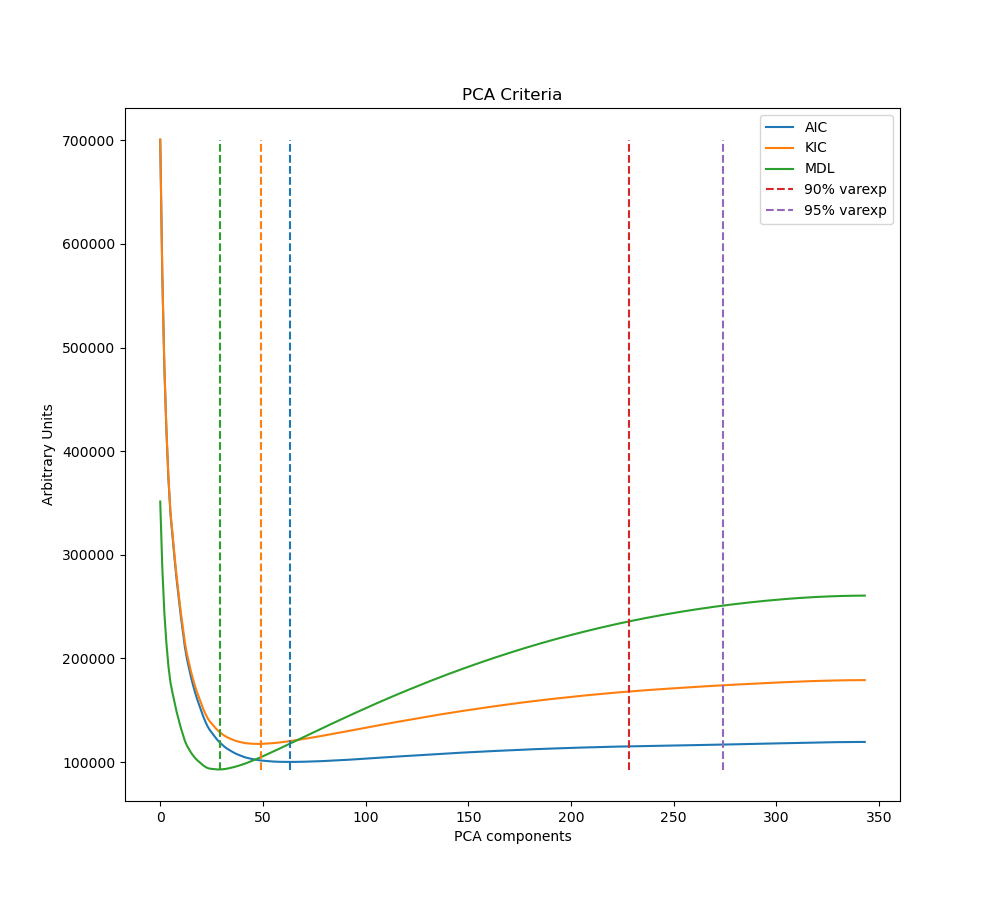
Your issue doesn’t relate to your choice of -tree but I’d recommend sticking with --tree kundu for now. -tree minimal as potential to be better, but it’s stil being evaluated and might change. If you ran the data using aic the output should include ./figures/pca_criteria.png and ./figures/pca_variance_explained.png These are plots of these three cost functions and the estimated components for each one. I’ve included a sample plot of pca_criteria You should see the AIC, KIC, and MDL cost function curve have a local minimum like in the figure and that minimum is the dimensionality estimate for each option. Look at these plots for successful and failed runs and see if any of the cost functions seems a bit more stable across runs.
Thank you so much for your quick responses! Here are my answers to your questions below (and see attached)
Re: minimally preprocessed echoes
Yes minimal preprocessed echos were also head motion corrected
Re: brain masks produced by tedana
Yes brain masks look ok
Re: number of volumes
For the first run there are 193 volumes, and 274 for the second run
Re: fmriprep and data quality
Yes fmriprep performed well
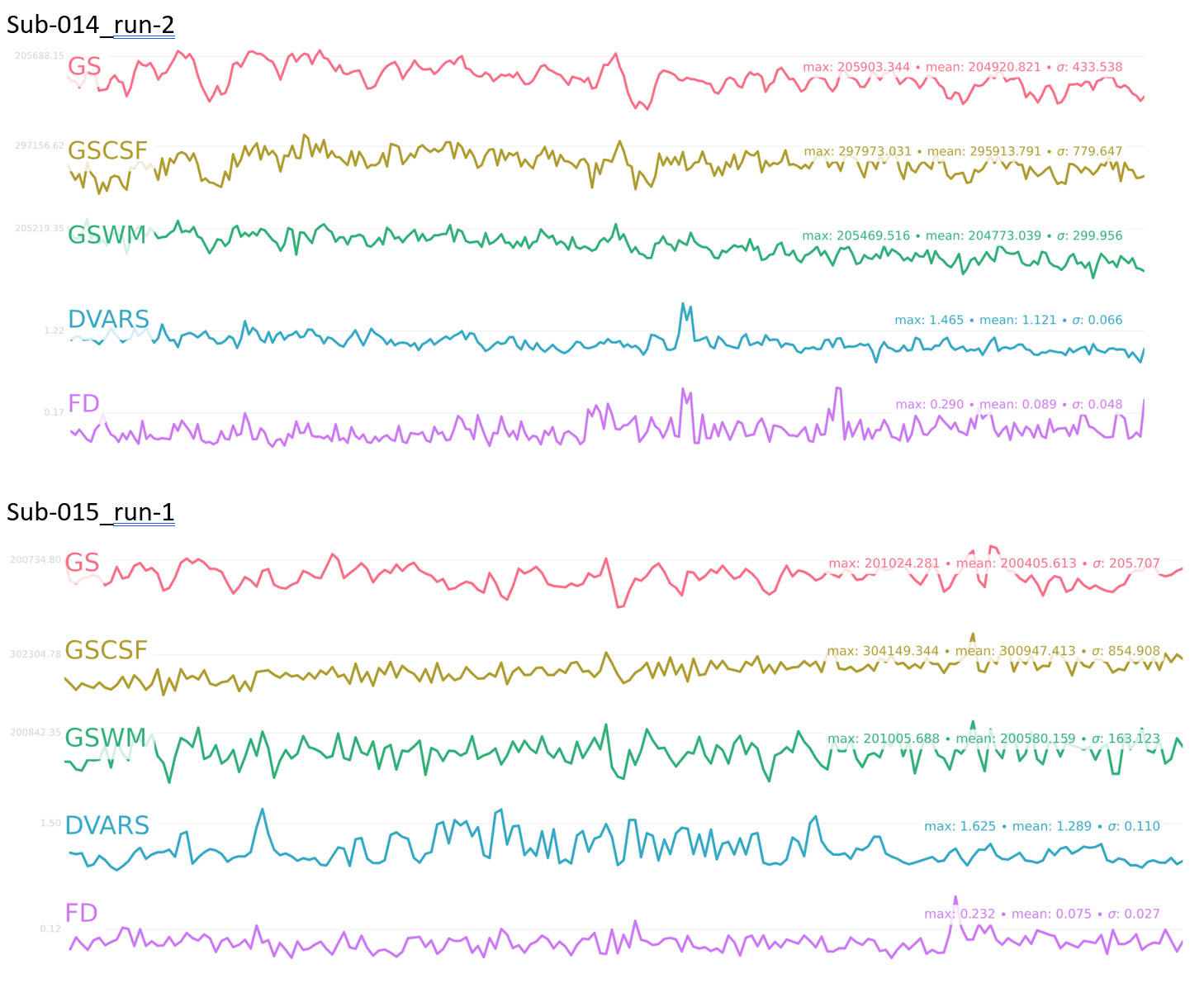
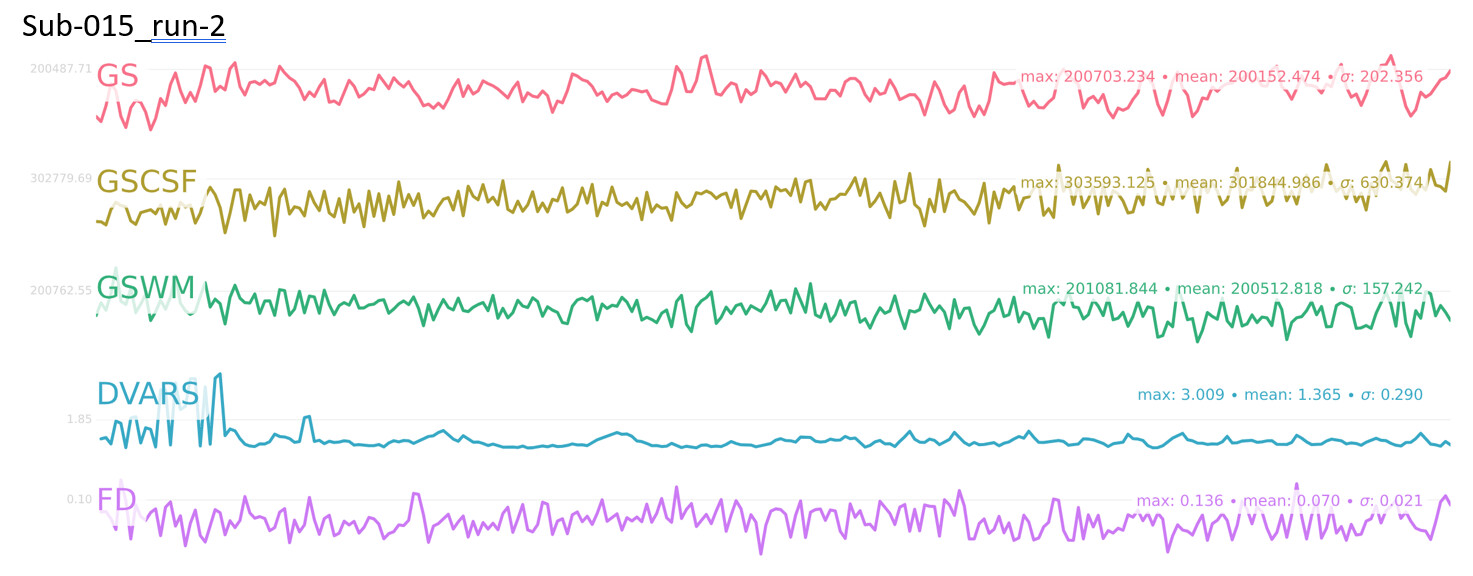
I think there was relatively high subject motion as this was a clinical population
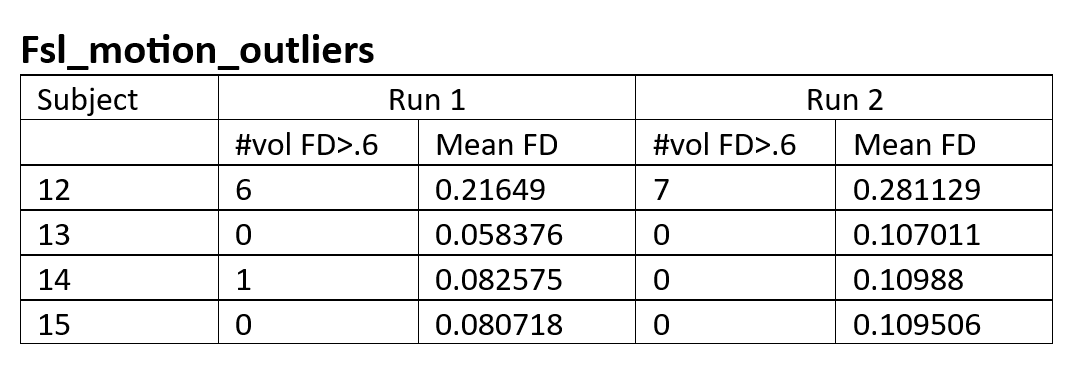
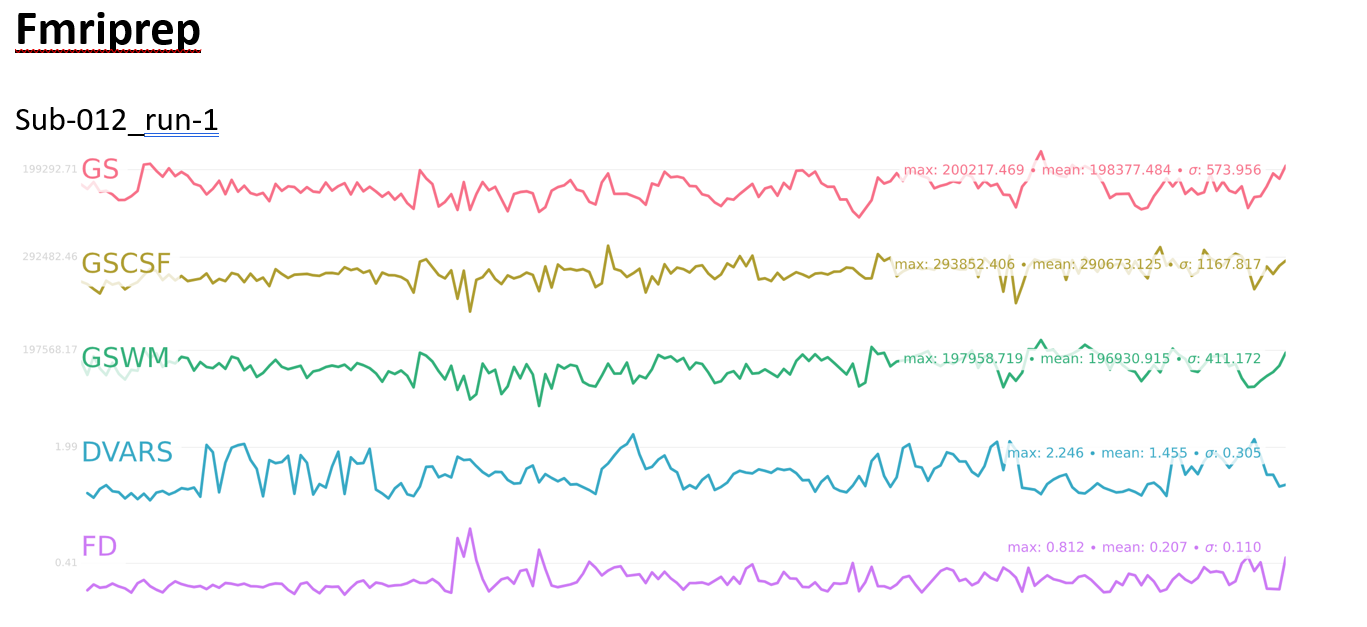
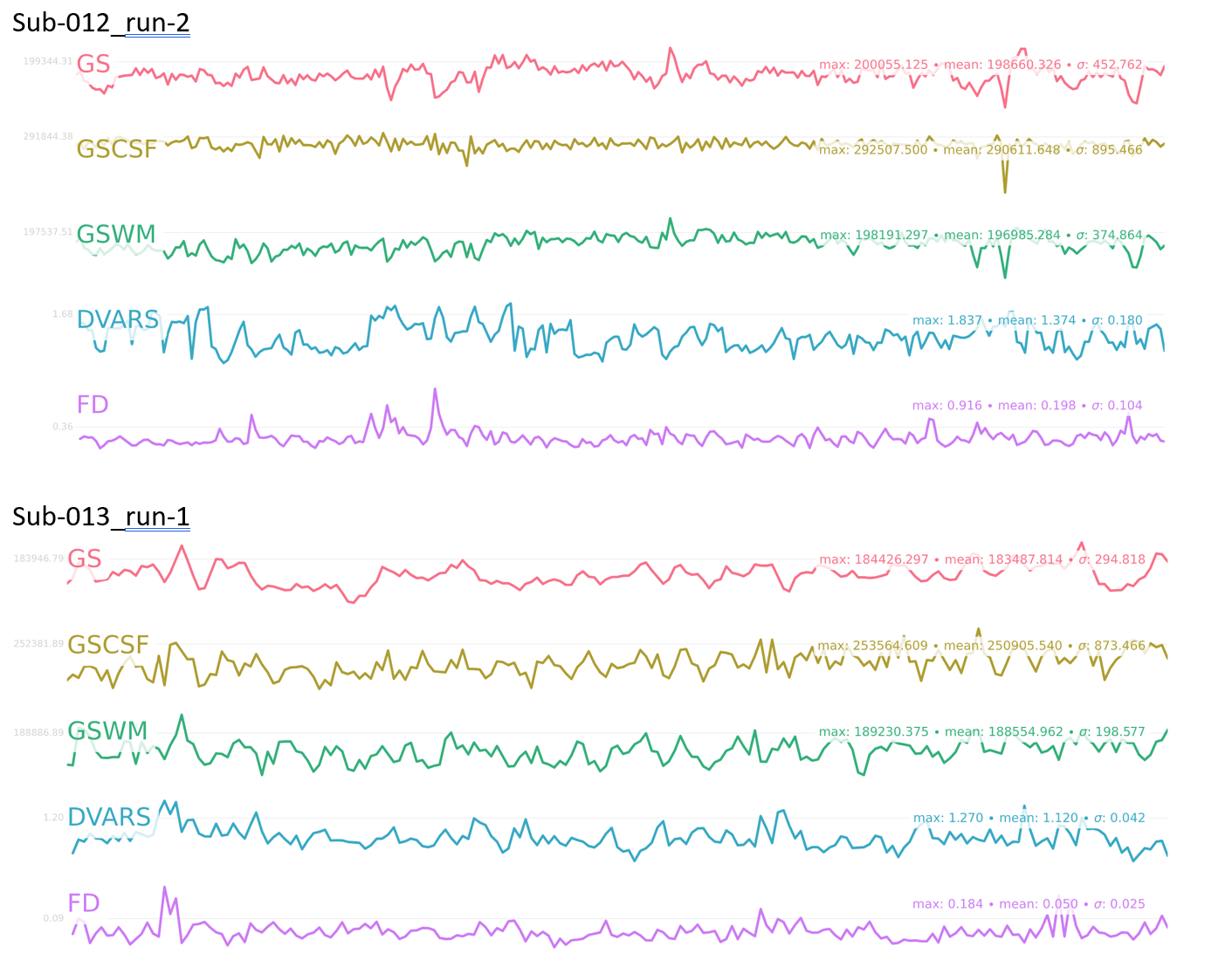
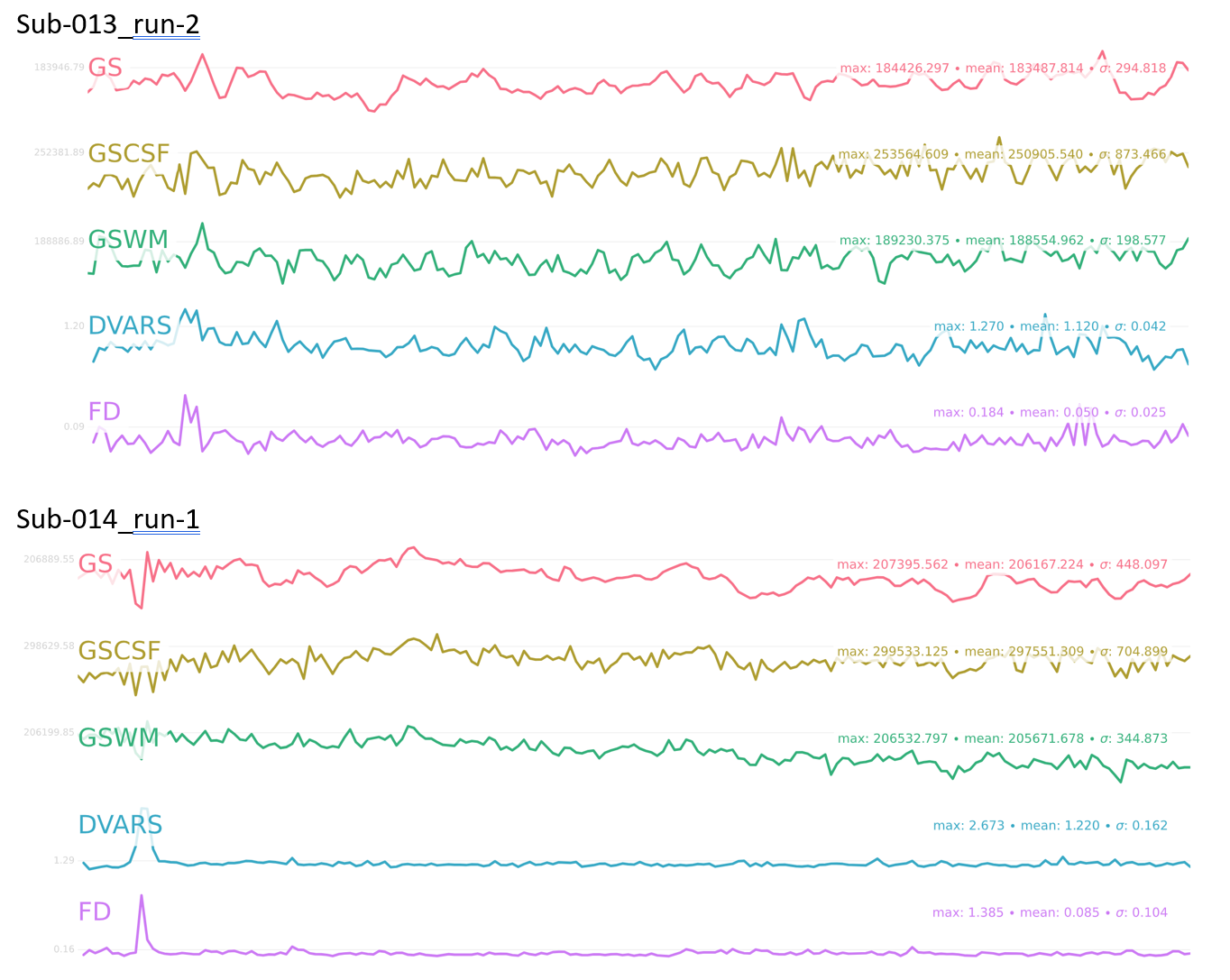
I’ve included some metrics for motion in the attached document, including # outlier volumes (FD>0.5) and mean FD for each subject/run, as well as the fmriprep BOLD summary figure with GS, DVARS, and FD timecourses for each subject/run
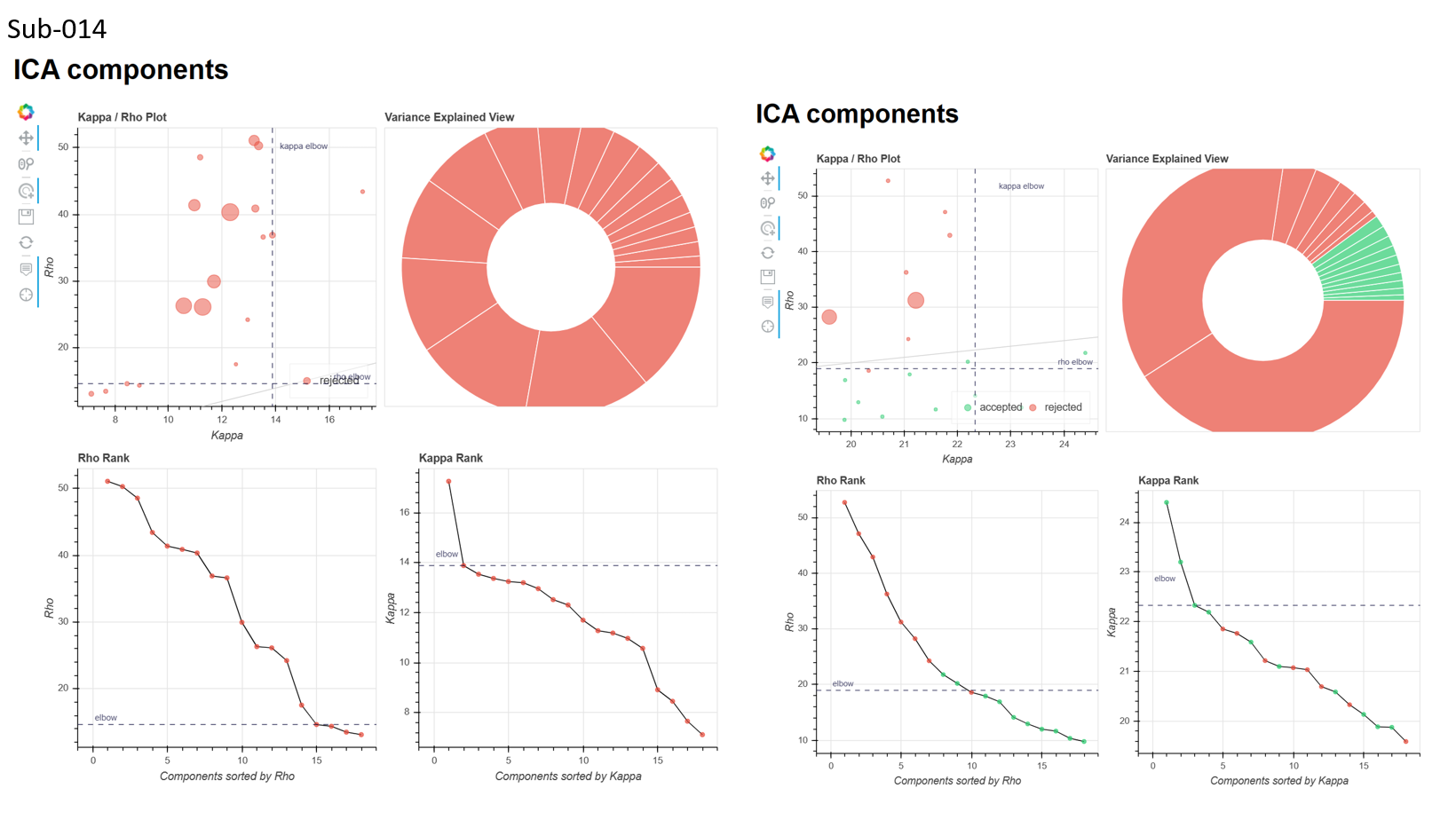
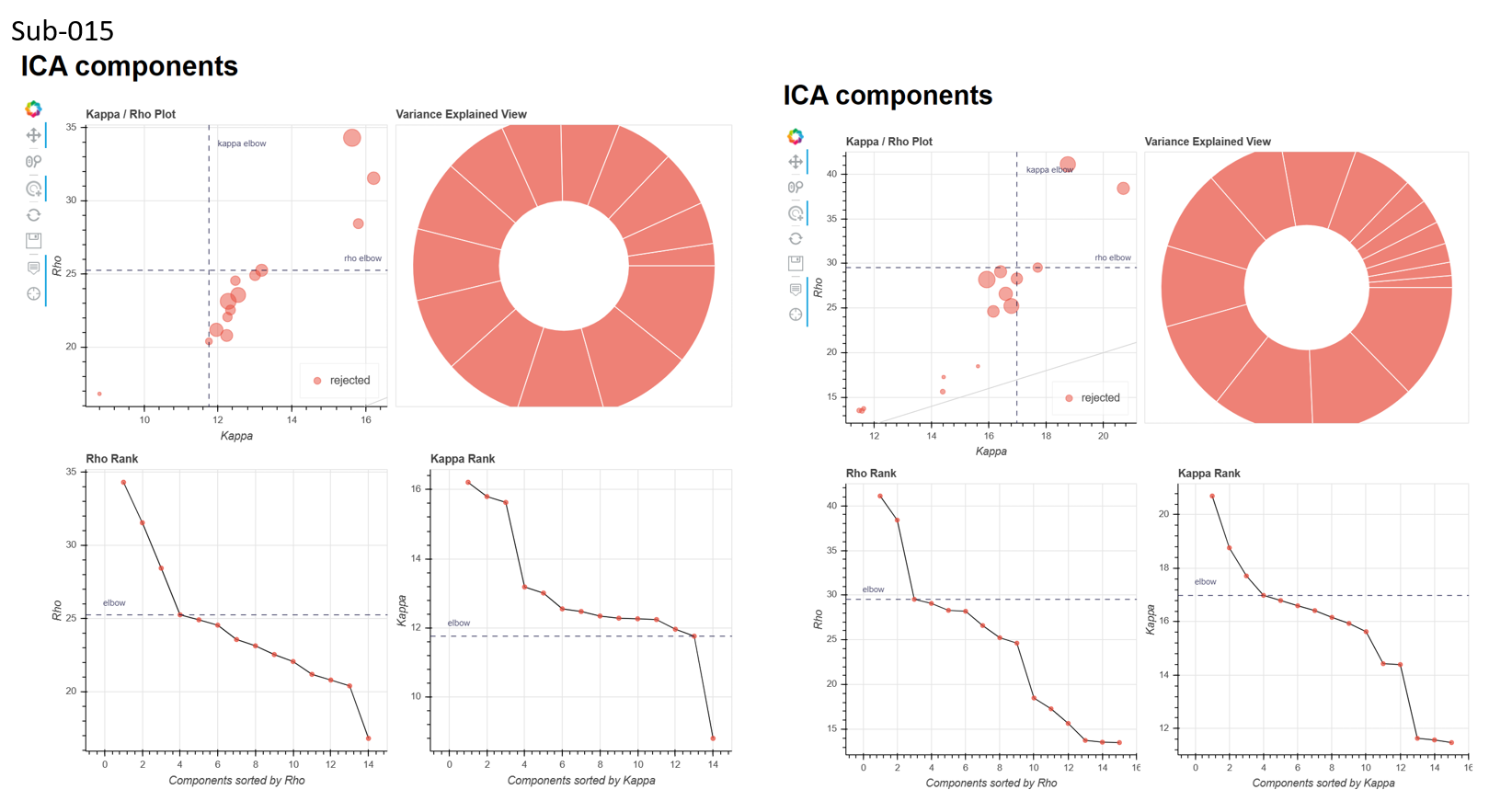
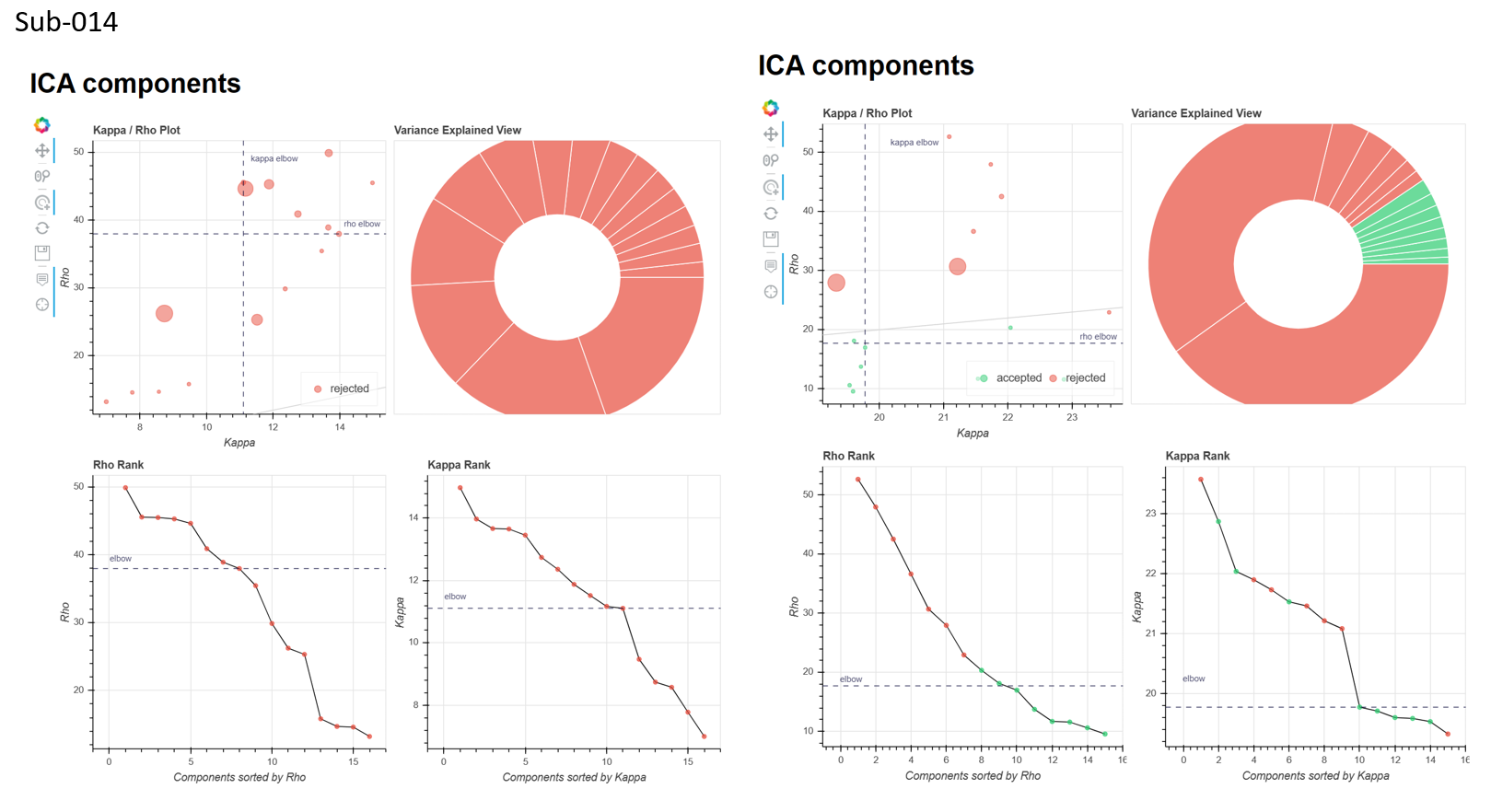
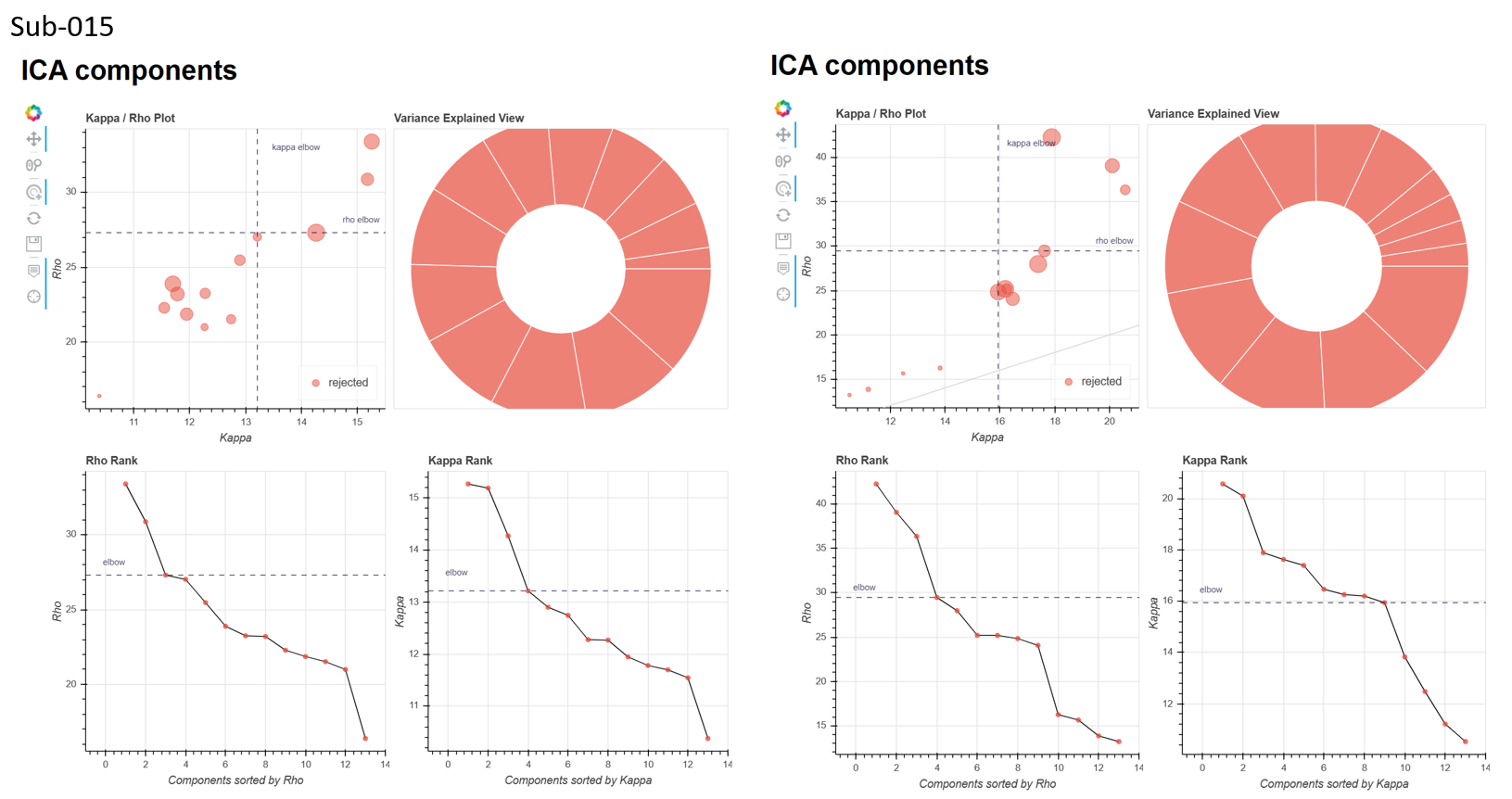
Looking at these metrics, I can’t really figure out the relationship between motion and ME-ICA converging. For instance, sub-012_run-1 had 6 outlier volumes (FD>0.5) but consistently converged across different --tedpca options/ on the other hand, sub-014_run-1 had 1 outlier volume (although it was a really drastic movement) and no BOLD components were found with the aic/kic options
Re: pca_criteria cost functions
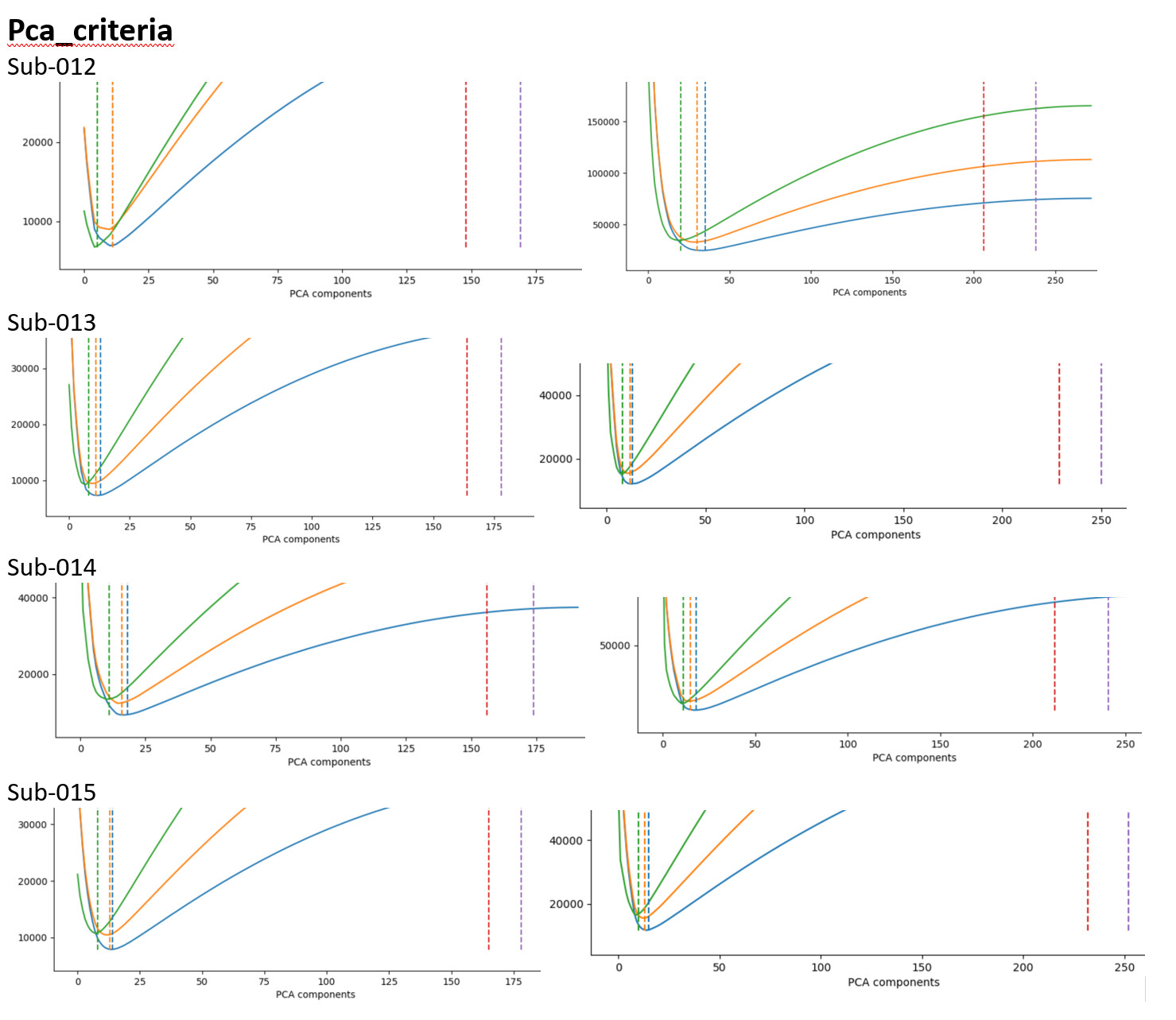
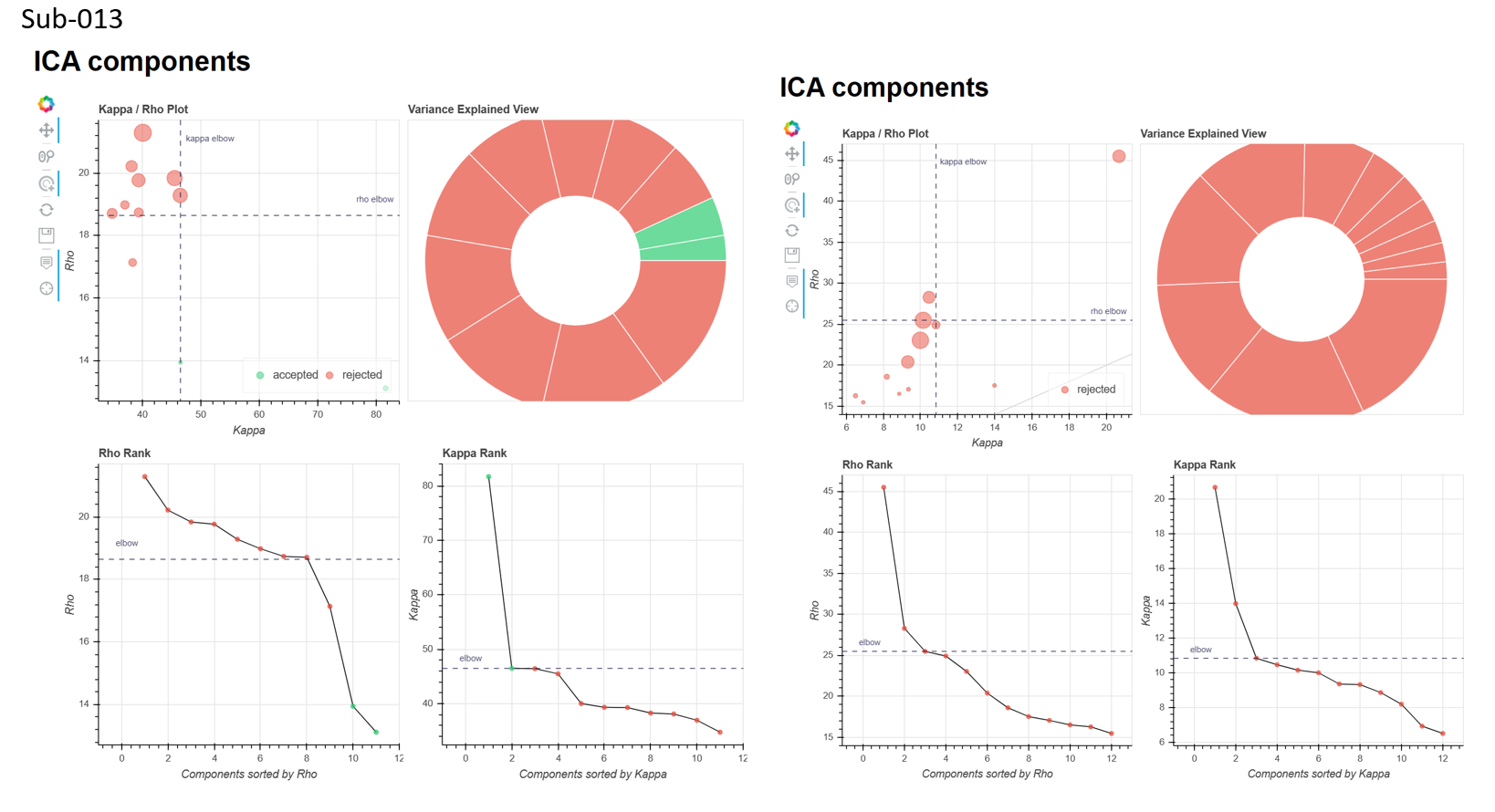
For this step, I wasn’t quite sure what part of the function curve to assess, so I included the pca_criteria.png figures for each subject/run in the attached document
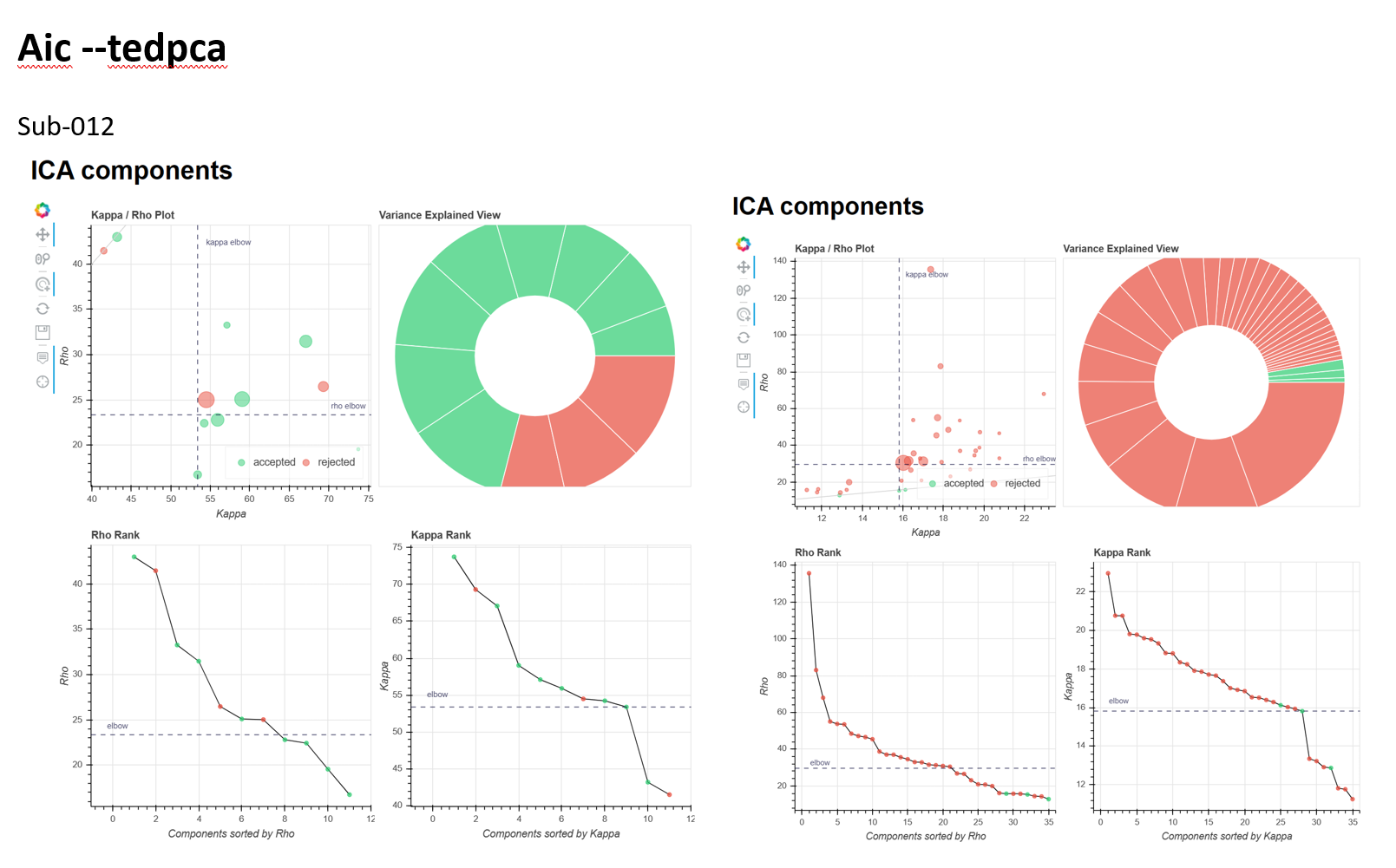
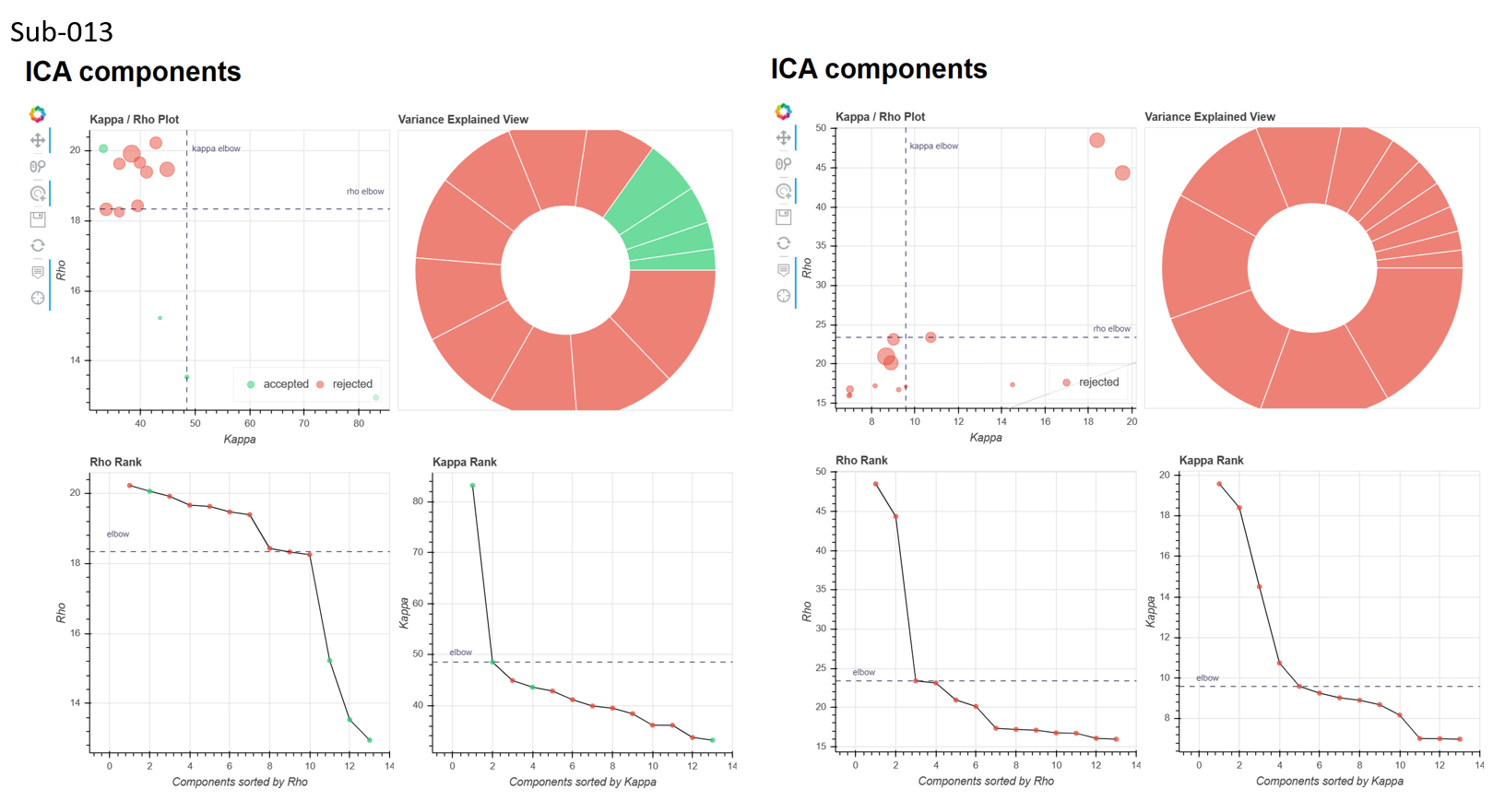
It seems that the local minimum is somewhat consistent across subjects within the same run (i.e. sub-012_run-1 & sub-013_run-1, but not between runs in the same subject (sub-012_run-1 & sub-012_run-2)
it seems like the dimensionality estimates for aic/kic/mdl are pretty similar? and the dimensionality seems too low?
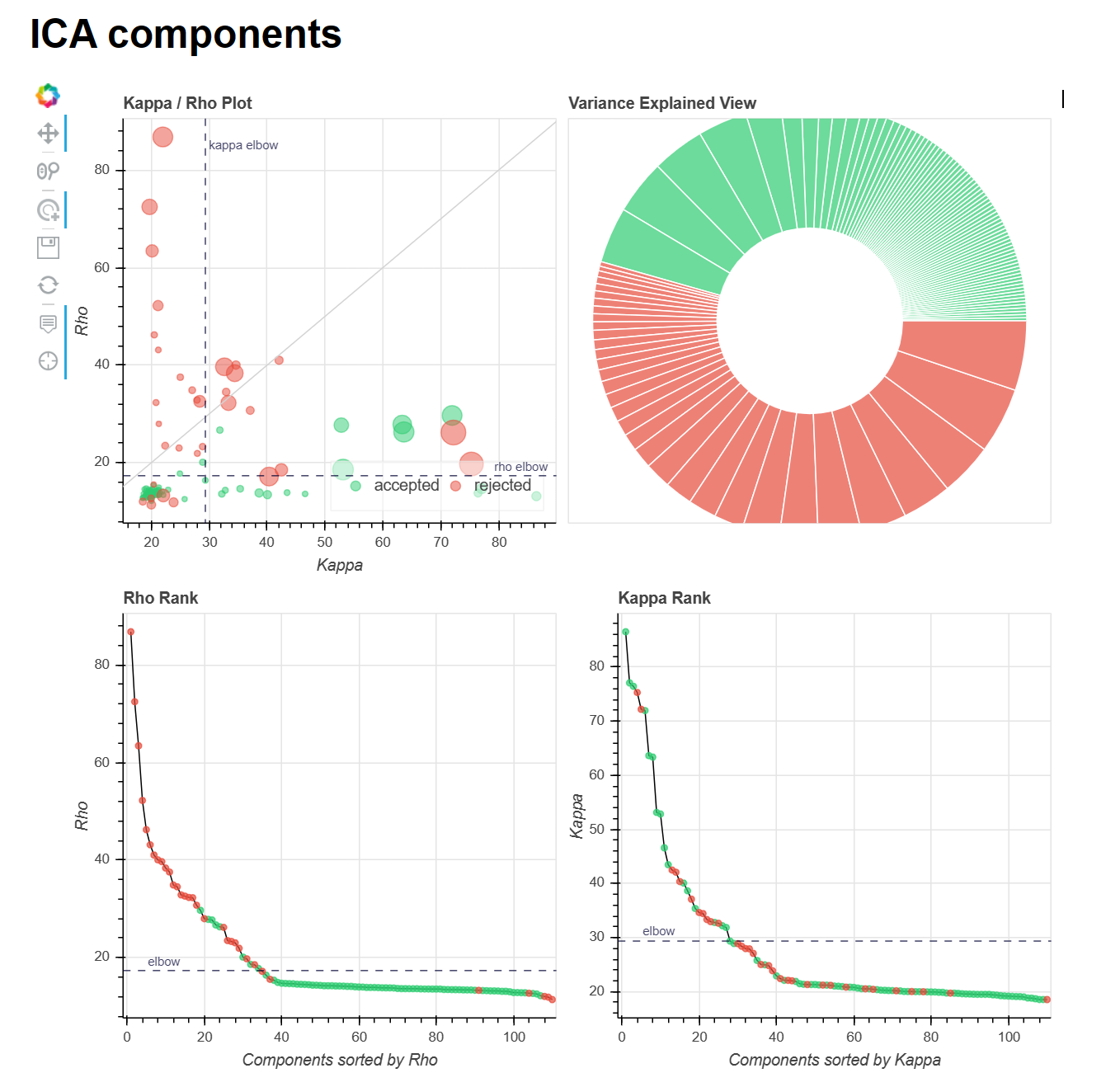
I’ve also attached the ICA components figure from the tedana report for the aic and kic --tedpca options (attached), it seemed like aic might have been a bit better, but still not great as there were many instances where no BOLD components were found
Thank you again! Looking forward to hearing your thoughts
I haven’t looked at a lot of the PCA Criteria curves, but almost all of those look shockingly different from the ones that I have seen. I can only speculate that this is due to the noise levels in the image being very high, but I’ll let others weigh in. Thank you for sharing all of those images, nothing else is jumping out at me very aggressively other than the extremely low number of comps (though I don’t use fmriprep so those outputs are new to me).
Would it be possible to share one bad subjects (maybe sub-015) unprocessed and post fmriprep data? so the 3 echoes before processing (anonymized, of course) and the 3 echoes after slice-timing, motion, etc? You’ve provided a lot here, but sometimes I just need to do eyeball stats.
The component estimation step is likely the issue. Those curve seem too steep and you’re ending up with too few components. The question is why. In conversations with someone else, someone suggested that the MA-PCA method we’re using was developed before the growth of acceleration and might be adversely interacting with some accelerated acquisitions. What levels of in-slice and multi-slice acquisition are you using?
That said, you also need more components to account for 90 and 95% of the total variance (the right two lines in the PCA criterion curve). This tells me that you’re data has more thermal noise than other data I’ve collected. That’s not inherently good or bad, but it’s another difference. You might want to look at some of your unprocessed data and temporal-signal-to-noise maps to see if anything looks problematic.
In the long-term, I’d love to figure out what MA-PCA sometimes gives bad results and find a solution. In the short-term, I’d suggest picking a fixed number of components, such as 1/4 (or 1/5) of your total number of volumes. I’d err on slightly more components because the method should work reasonably well if the data are split into slightly more components than necessary, but you’re having problems with too few components to cleanly model variation in the data. This is NOT ideal, but it should work and should reliably give you stable results with noise removed.
Thanks for all your replies. Since my run length are quite different, 193 volumes for run 1 vs 274 volumes for run 2. Should I run Tedana separately for Runs 1 and 2 when picking a fixed number of components? Or should I concatinate the runs together first?
I would apply @handwerkerd’s idea to each run independently - as in run tedana seperately. As it is just a guess, being slightly wrong shouldn’t be the end of the world. So, try 1/4th of the number of timepoints in each run.
I’m not sure how tedana would behave with concatenating runs - I’m personally interested in this, however this probably isn’t the place to test such an approach.