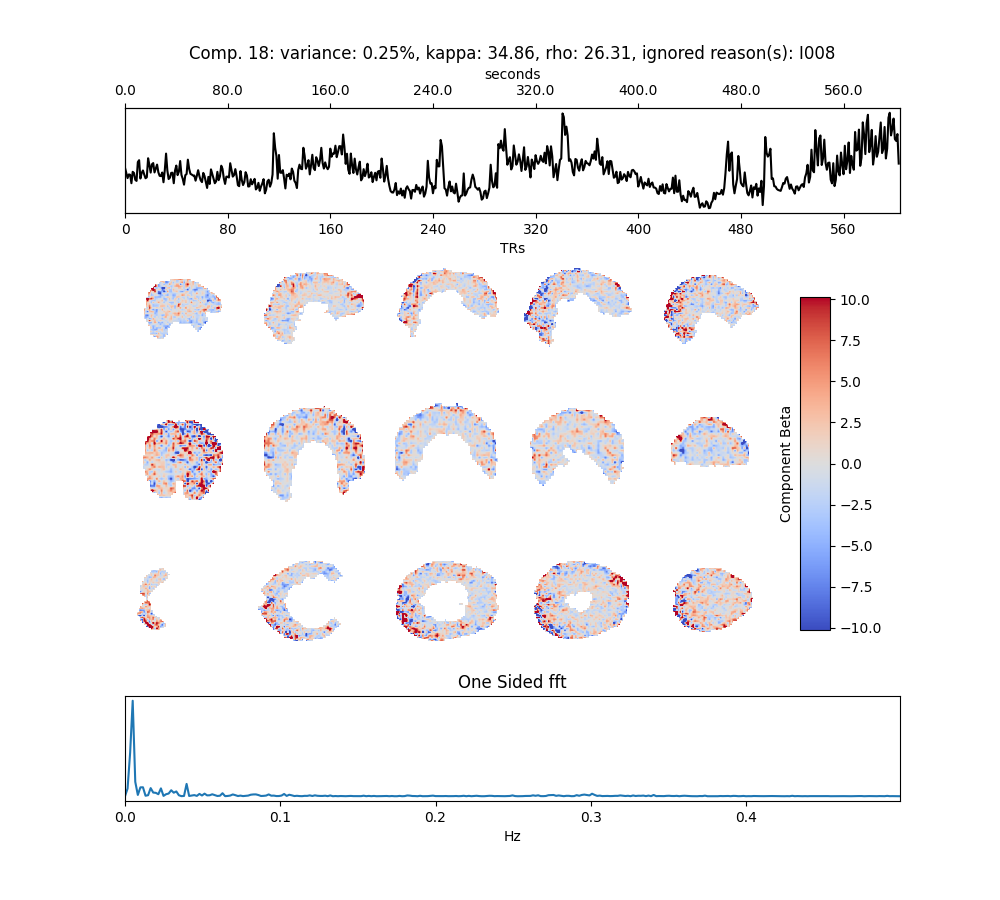
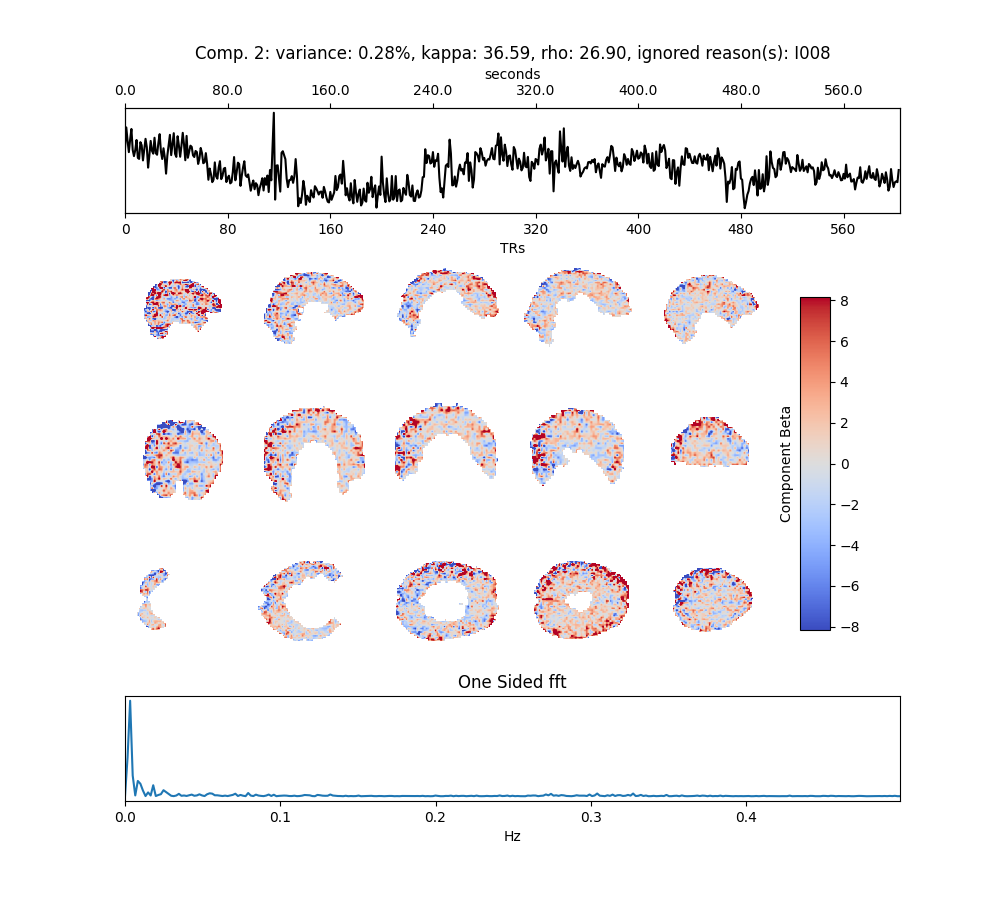
I am preprocessing resting state Multi Eecho fMRI data and so far have minimally preprocessed with fMRIPrep and have fed them into tedana.
Regarding Tedana’s output, I have seen in previous topics that some components might have been classified as noise while they might be signal. Is there any framework for deciding on which components to add to the savings list from the ones already classified as noise or ignored? For example, the two components attached here are ignored, but it seems that they have the potential to be accepted regarding their power spectrum, timeseries and the spatial map.
I highly appreciate your clarification and guidance on that.
Regards,
Ali
All components classified as ignored are retained in the denoised time series. The idea is that these are components that may or may not contain useful signal, but are too small to decide whether to reject so just “ignore” and keep them. This is confusing terminology. In a planned update to the code, all components currently classified as ignored will be classified as accepted and a separate tag will explain why they were accepted.
Thank you very much Dan, it indeed clarified most of the issue. I do have a further question, I am not sure how to define whether a component is mistakenly classified as noise or not when visually checkeing the outputs.
I consider some visual check points e.g., the power spectrum to be dampped at higher frequencies, the spatial map not to include CSF and Wm and the time series to not look weird, but some times the rejected components are kind of similar to the ones ignored and I can hardly tell whether teh component is mis-rejected or not? Should I be too peaky or I should go a bit easier and trust the software?
Some of this depends on your goals with the data. If the risk of removing something with relevant signal is greater than the risk of keeping some unnecessary noise, then always lean towards accepting anything you’re unsure about.
I know the current selection method is a bit brittle and misclassifies so I don’t blindly trust it and I’m working on more stable alternatives. That said, I tend not to manually change classifications because that’s adding some subjectivity. Generally, when I’m seeing big failures, there might be something else wrong and I try to figure out what’s happening. Sorry that this is not a more definitive answer.