Following on @kevinwli’s great initiative, a thread to point out errors and sources of confusion in preparation for the tutorials of W1D4.
Hi @FedeClaudi ! I noticed that in the previous thread several people asked to make it available to students. This however is not possible if the category is set to TAs . Can you change category or simply make a new post, so that everyone on the forum can see it, and not just TAs?
2 Likes
Thanks for letting me know. I changed the category, is it okay now?
2 Likes
Yes, I think now both students and TAs will see it. Thanks a lot!
1 Like
Thanks @FedeClaudi! Let’s make the materials more accurate.
First, here’s a notice from another post:
T1, Section 2.1 Exercise 3
In the final matrix notation, there should be a sum over \lambda, or 1^T\lambda.
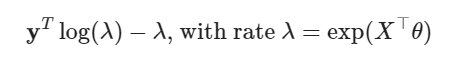
T2, Section 4.1, Exercise 3
Be careful that we switch back to l-2 penalization here!
2 Likes
Not a problem with the notebooks per se, but this could be a nice primer on norms and regularizations: https://medium.com/@vladimirmikulik/edgy-norms-outliers-and-sparcity-924038812203
1 Like
A couple things about Tutorial 1 Section 1
In the video at some point y_t is said to be the “binary” spike count:

however that can’t possibly be true given that both lambda and nu are scalars.
I know that the point of this exercise is to realize that this model can’t do a good job of predicting spike count, but if someone is trying to follow along with the video they might be confused (I know I was…): how could y_t be binary ?
Later in the video the spike trigger average (STA) is described as X.T y, however in the text in the bonus section it is (correctly ?) defined as (X.T y)/sum(y) .
2 Likes
A question on “cross_val_score(model, X, y, cv=k)”. I know in the tutorials the “model” is not yet trained. But in practice can I also use a pre-trained model here?
Thanks for pointing this out! I think it’s recommended that for mistakes like the one in T1, Section 2.1 Exercise 3, we should submit an issue on NMA github for keeping track of things, and they can fix those in the near future 
3 Likes
Yeah, the binary thing is confusing, but I think the count should count – it’s counting the binary numbers within a window.
I’m appalled that X.T y is called STA… it’s more like the correlation/covariance.
1 Like
Ok, I think it’s already fixed.
If there is already trained the model, it can only be tested on one fold, right? Then perhaps manually do it manually.
thanks. i think i am a bit confused here. say i want to make a regression model with penalty, so i use CV to train my model on the training set, and this should give me the optimal hyperparameter, and does it at the same time give me the optimal set of parameters for me to test on the test set? Or is there a separate step to perform before the final testing?
In the W1D4 Intro video, I think the expression on the slide at 14 minutes for Poisson GLM log likelihood may be incorrect. I believe the substitution lambda_t = theta.T x_t has been made, when the correct substitution is lambda_t = exp(theta.T x_t).
I’ve asked the content creators to come to the americas help-desk tomorrow at least (too early potentially for europe)
1 Like
Hi,
thanks for pointing out the STA thing. That is a mistake. I forgot to divide it by sum(y). Sorry about that. For the binary y thing, I agree it’s a bit confused especially for people who already have some knowledge about poisson for spikes. It’s actually a bit tricky to layout these contents while maintaining the continuity. and I believe for beginners who don’t have much knowledge about noise, I hope it might not be too abrupt for them to see Gaussian for binary counts. this can be a helpful example to show that if you naively assume gaussian, you don’t get a good fit.
3 Likes
Hi,
Thanks for replying!
That’s fine, I was just pointing those things out so that if discussion gets bogged down on these issues during the tutorial we TA are aware of the issue and can swiftly move it forward.
It’s perfectly understandable that some small mistakes will be undetected during content creation.
As you say, experts won’t be too confused by it and most likely beginners won’t notice, so it shouldn’t be a problem 
1 Like
would you also agree that in video 1 6:45, there should not be a d in the first term?
Another point that I found a bit confusing in W1D4 - T1 - exercise 3 function fit_nlp :
The initial iterate for minimizing the negative log MLE is called x0 which might be confusing because this is similar to the name of the predictor matrix. Might be better to call it theta0 for consistency.
1 Like
Something some of the students got confused about from T1E3:
Our function returns yhat = np.exp(X @ theta) and throughout the videos and text y is used to refer to the spike count while X @ theta in the text is called lambda or firing rate: 𝜆=exp(𝑋⊤𝜃).
So our function really returns lambda which would then be the parameter of the Poisson distribution, but we never bother with that and just plot lambda. The students where confused about why do we just plot lambda.
My answer is that in a Poisson distribution lambda is the mean of the distribution so plotting that gives a good intuition of the model’s predictions, but I’m not sure if this is the correct answer.
5 Likes