Thanks @FedeClaudi! Let’s make the materials more accurate.
First, here’s a notice from another post:
T1, Section 2.1 Exercise 3
In the final matrix notation, there should be a sum over \lambda, or 1^T\lambda.
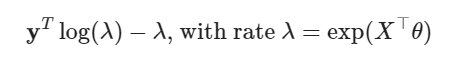
T2, Section 4.1, Exercise 3
Be careful that we switch back to l-2 penalization here!