Hi all, I submitted this already as part of my introduction post, but since I figured it probably didn’t get the right attention over there, I am now shamelessly reposting it here. 
I just finished doing a fmriprep v20.2.1 multi-threading benchmark on our HPC cluster, which I figured may interest some of you (I hope). Here is what I found:
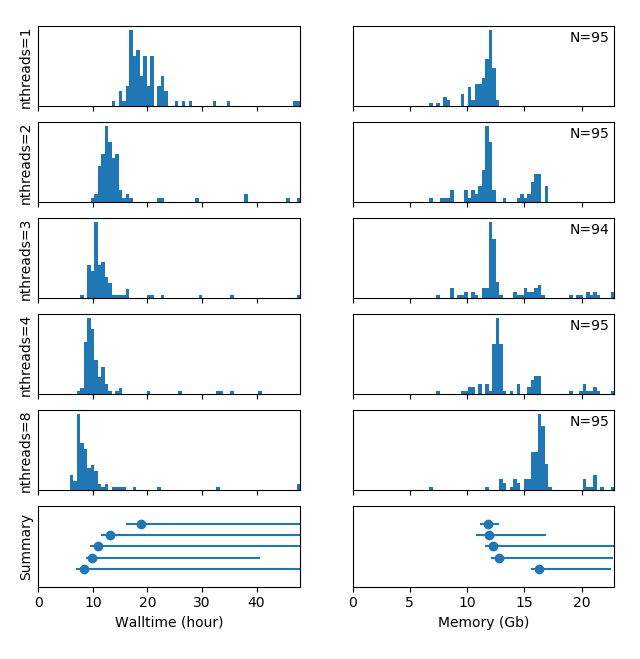
Jobs were submitted using e.g.
qsub -l nodes=1:ppn=3,walltime=48:00:00,mem=28000mb,file=50gb -N fmriprep_sub-P004 <<EOF
cd /home/mrphys/marzwi
unset PYTHONPATH; export PYTHONNOUSERSITE=1; singularity run --cleanenv /opt/fmriprep/20.2.1/fmriprep-20.2.1.simg /project/3017065.01/bids /project/3017065.01/bids/derivatives participant -w \$TMPDIR --participant-label P004 --skip-bids-validation --fs-license-file /opt_host/fmriprep/license.txt --mem_mb 28000 --omp-nthreads 3 --nthreads 3
Conclusions:
- The speed increase is not very significant when increasing the number of compute threads above 3
- The majority of jobs of the same batch require a comparable walltime, but a few jobs take much longer. NB: The spread of the distributions is increased by the heterogeneity of the DCCN compute cluster and occasional inconsistencies (repeats) in the data acquisition in certain (heavily moving) participants
- The memory usage of the majority of all jobs is comparable and largely independent of the number of threads, but distinct higher peaks in the distribution appear with an increasing number of threads
I would love to get some explanation and/or comments from you on the irregular / multi-modal memory usage of my multi-threaded jobs!
p.s.: If you are really interested in this topic, all the code to distribute the fmriprep batch job over an HPC cluster (fmriprep_sub.py), as well as the data (i.e. PBS logfiles) and code to generate the benchmark plot (hpc_resource_usage.py), can be downloaded from github.