Hi, I’m a system analyst providing support to Cedars Sinai Hospital (specifically their high performance computing clusters).
I’m here just to get a little help with Heudiconv, since the Stanford Heudiconv walkthrough says to ask questions here.
I was following the tutorial, but found that the output being created didn’t match what I was seeing. Specifically, after the first step (running heudiconv with “-c none”, the heuristic.py file it created did not have any of the custom code seen in the example.
** for idx, s in enumerate(seqinfo):**
** if (s.dim1 == 320) and (s.dim2 == 320) and (‘t1_fl2d_tra’ in s.protocol_name):**
** info[t1w].append(s.series_id)**
But the file which was actually generated has the following code:
** data = create_key(‘run{item:03d}’)
info = {data: []}
last_run = len(seqinfo)
for s in seqinfo:
"""
The namedtuple `s` contains the following fields:
* total_files_till_now
* example_dcm_file
* series_id
* dcm_dir_name
* unspecified2
* unspecified3
* dim1
* dim2
* dim3
* dim4
* TR
* TE
* protocol_name
* is_motion_corrected
* is_derived
* patient_id
* study_description
* referring_physician_name
* series_description
* image_type
"""
info[data].append(s.series_id)
**
I"m using the dataset referred to in the tutorial. Has that set changed since the tutorial was written? Is there some hidden step to actually create the heuristic.py file? Am I missing an option when running heudiconv? I’m running with heudiconv in Python 3.8.0, rather than using the docker example in the tutorial, but I got the same result from trying the docker method.
The command was “heudiconv -d sub-{subject}/ses-{session}/SCANS//DICOM/.dcm -o nifti -f convertall -s 01 -ss 001 -c none --overwrite”.
The heudiconv version is 0.80
The OS is Centos 7.5.1804
This is 27 years old Mujahid Alkausari from Pakistan
Really excited to wonderful life with the research community here but before the journey begins, I would like to share a little about myself and the reasons for being in this very diverse group.
For the last 4 years since I did my graduation in the field of Computer Science mid of 2017, I have been establishing genuine interest with great compassion and dedication to understand, while experimenting my own mind, that how creativity manifest innovative solutions through imagination with the aim to learn mapping them to the external world and vice versa; viewing it in terms of inborn and external variables that shape the whole scenario for us. During my explorations, I recently came across very useful knowledge sources about neuroscience in the digital spaces which further boost my confidence to continue pursing career in this side. For this purpose, as experienced programmer, I’m learning Artificial Intelligence models with Python to be able to utilize it in neuroscience because I have developed strong mathematical background throughout my educational journey. Besides, I availed semester study program as a County Exchange Student from Pakistan under the Global UGRAD program at Troy University AL, USA in 2015, since than I have been actively taking part in various international conferences on digital literacy, entrepreneurship, business, science and technology.
With all that said, I’m looking forward to joining the research community so that I can continue my journey that will not only benefit me but the whole community and the society in general.
I’m a physicist from the Donders Institute at the Radboud University in the Netherlands. I’m involved in setting up MR acquisition protocols, but mostly do my work on processing the data that comes out. To that end, I developed a very user friendly (it comes with a#gui ;-)) python package named BIDScoin for converting that data into #bids.
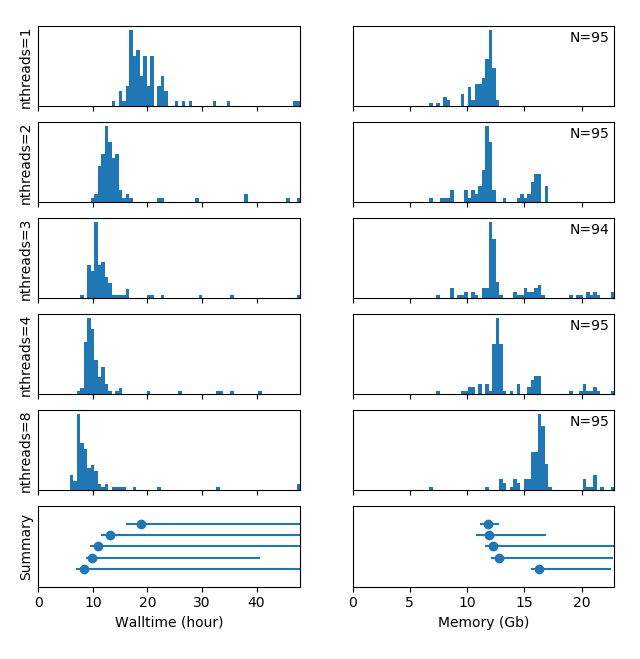
I also support a lot of the #fmriprep processing in the center and made a little tool to process bids dataset on our #hpc cluster (using #singularity containers). I actually just finished doing a fmriprep v20.2.1 #multi-threading#benchmark on our cluster, which I figured may interest some of you (I hope) and which is the reason why I post this here. Here is what I found:
The speed increase is not very significant when increasing the number of compute threads above 3
The majority of jobs of the same batch require a comparable walltime, but a few jobs take much longer. NB: The spread of the distributions is increased by the heterogeneity of the DCCN compute cluster and occasional inconsistencies (repeats) in the data acquisition in certain (heavily moving) participants
The #memory usage of the majority of all jobs is comparable and largely independent of the number of threads, but distinct higher peaks in the distribution appear with an increasing number of threads
All the details and code to distribute the BIDS job on the HPC cluster (fmriprep_sub.py), as well as the data (i.e. PBS logfiles) and code to generate the benchmark plot (hpc_resource_usage.py), can be downloaded from github.
Would love to get your ideas and/or comments on the irregular memory usage of my multi-threaded jobs!
Hi, I see you haven’t received any responses yet, so I’ll go ahead and put on a few tags for you. We have >8k people, so posts get lost pretty easily… #HPC#heudiconv
Hi Mujahid, spot on choice of field, a lot is happening in the interface between AI and Python and neuroimaging, right now. If you haven’t yet tried it, I recommend the Semantic Scholar paper search. Here is a recent example, Henschel et al. 2020
Hi Francesca, and welcome to NeuroStars! You are lucky in your choice of programming languages, the R community is large and friendly + good att offering learning resources, here are some tips. MATLAB also has a lot of FAQs and other user resources , and we have an open Data Science in MATLAB course on NeuroStars.
My name is Leo, I’m a early-stage PhD student working in the field of Consumer Neuroscience at the University of Rotterdam. Currently I am analyzing fMRI datasets, either writing own scripts or making use of some of the great tutorials and packages that the community has developed. In the past I also gathered some experience working with fNIRS, both in research and industry. Happy to try and answer any questions on that topic, as for fMRI I look forward to following topics on this forum and occasionally asking a question myself.
I’m Roxane and I am a graduate student in Belgium and a currently working on a project where we are using BIDS and fMRIprep for the first time, so I am looking for community of people that will help each other figure everything out!
I look forward to communicating with you all
hi everyone
my name is Arash, I am getting a master’s in Artificial Intelligence. I am interested in simulating everything the brain does! I am very new to the field and will probably ask a lot of questions already asked my first question thank you all in advance for answering
just yesterday I said to a friend that I wish there was a stackoverflow for neuroscience and today I found this site
Hi this is James
I have PhDs in Cognitive Neuroscience (U. Trento, Italy) and Sanskrit/Tibetan (Columbia U, NY), with postdoctoral training in both fields. One primary interest in neuroscience is understanding functional neuro-circuitry using MRI methods. Broader research interest is focused on integrating knowledge systems from both fields.
I’m a physicist, currently - postDoc at the Center for Neuroscience Imaging Research (CNIR, SKKU). I’m doing ultra high filed MR research on small rodents (mice), building MR compatible optical sensors for neuronal measurements (fiber photometry). I’m highly interested in implementation of BIDS and utilizing nipype for MR data processing.
Hi,
I’m Shubh, currently an Undergrad in the Computer Science Dept. of Indian Institute of Technology-Bombay. I’ve worked on many ML Projects of my own in past years and have learned a lot aabout ML and TensorFlow.
Looking forward to contributing to this vibrant community(with an aspiration for GSoC!)
Hi everyone, I’m Omar Elsherif. I study Medical Informatics at Faculty of Computers & Artificial Intelligence Benha University in Egypt. I want to work in neuroscience research using the power of AI and Data science. I’m in my second year at college now and during the first year, I learned a lot about machine learning, deep learning from Coursera and DataCamp. I also take an advanced nanodegree in Data Analysis from Udacity. I joined Neuromatch Academy as an interactive student during the last summer. I want to join DIPY in GSoC 21 under the umbrellas of INCF. I most interested in Image processing and visualization so I want to join the project titled (Extend DIPY Horizon workflow for Visualization) so any tips or something to do in order to start contributing here?
Here is my linkedin profile to keep in touch: https://www.linkedin.com/in/omar-elsherif-data-science/
Hi, I am Purva Chaudhari, third year undergrad in Computer Science from India. I have worked on Object Oriented Python, c++, ML, Tensorflow, Pytorch, and data science algorithms. Looking forward to working on Neuroscience and participate in GSOC 2021!
Hi , I am R Tharun Gowda , currently pursuing undergrad in Indian Institute of Technology (BHU). I’m a AI and machine learning enthusiast mainly in the field of computer vision and reinforcement learning. I have always found it interesting to use AI in field of medical diagnosis and its huge applications in the field of neurology, intend to be part of this community and also looking forward to be a part of GSOC’21.
Hi, I’m Fran Hancock in Switzerland. I started a PhD in Neuroimaging Research / Computational Neuroscience at King’s College London. I’m looking at the dynamical complexity of resting state and hope to investigate both synchrony and information dynamics in rs-networks. Due to COVID restrictions, I need to ‘self-learn’ everything from fMRI preprocessing through to information theoretic analysis. I found this site while looking for information on HCP data/directory structure and BIDS.